Why this matters
Webhook spikes, flaky networks, and duplicate deliveries can break AI automations. A dedicated gateway absorbs external events, validates and normalizes payloads, and reliably triggers downstream AI tasks—without blocking third‑party timeouts.
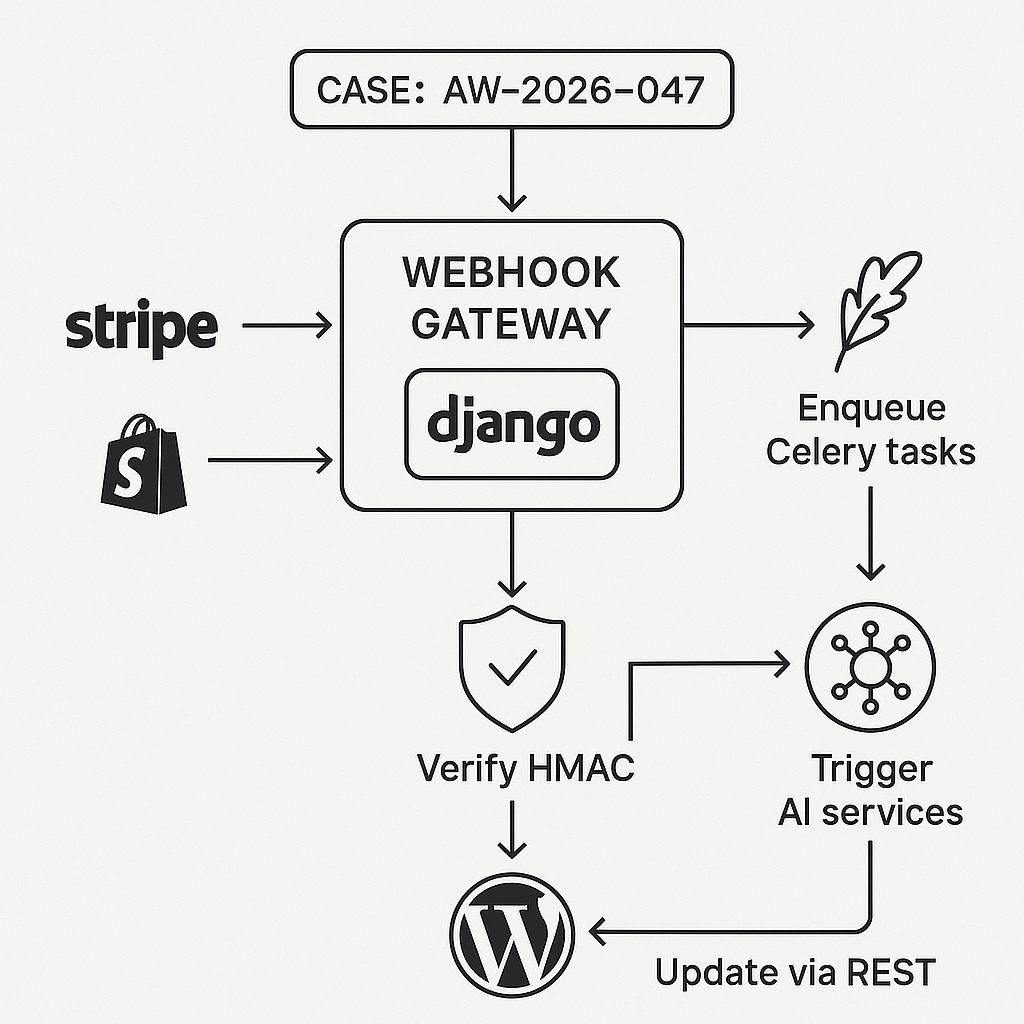
Reference architecture
– Sources: Stripe, Slack, HubSpot, Shopify, WordPress (outbound)
– Ingestion: Django REST API behind Nginx/Cloudflare
– Queue: Celery + Redis (or RabbitMQ)
– Storage: PostgreSQL (events, dedupe), S3-compatible blob storage (optional payload archive)
– Workers: Celery tasks for AI calls, CRM updates, email, etc.
– Destinations: WordPress REST API, CRMs, internal services
– Observability: Sentry, OpenTelemetry, structured logs, metrics
– Security: HMAC signature verification, JWT between services, IP allowlists, secrets rotation
Django models (idempotency + audit)
– WebhookEvent(id, source, event_type, signature_valid, idempotency_key unique, status [received|queued|processed|dead], received_at, processed_at)
– WebhookPayload(event fk, raw_json jsonb, headers jsonb, archive_url nullable)
– TaskResult(event fk, task_name, attempts, last_error, duration_ms)
Ingestion endpoint (Django REST Framework)
– Path: POST /api/hooks/{source}/
– Steps:
1) Read raw body bytes
2) Verify signature (per source)
3) Extract idempotency key (header or compute from body hash)
4) Insert WebhookEvent with unique constraint on idempotency_key
5) Persist payload (jsonb) and optionally stream to S3 if >256 KB
6) Enqueue Celery task with event_id
7) Return 200 quickly (<200 ms)
Example signature checks (Stripe + Shopify)
– Stripe: compute HMAC-SHA256 over “timestamp.body” using endpoint secret; enforce tolerance window
– Shopify: HMAC-SHA256 over raw body with shared secret; compare Base64-encoded signature
Django view (trimmed)
– Use raw_body = request.body, do not json.loads() before HMAC
– On IntegrityError for duplicate idempotency_key, return 200 to be idempotent
Example code (signature utils)
– Stripe:
– payload = raw_body.decode()
– signed = f"{timestamp}.{payload}"
– expected = hmac.new(secret, signed.encode(), hashlib.sha256).hexdigest()
– compare_digest(expected, provided)
– Shopify:
– expected = base64.b64encode(hmac.new(secret, raw_body, hashlib.sha256).digest()).decode()
Celery tasks pattern
– receive(event_id)
– fetch event + payload
– parse into typed schema (Pydantic/Django validators)
– route by event_type
– call AI services (e.g., OpenAI) with retries/backoff
– write TaskResult and update event.status
– push results to WordPress via REST
Retry and backoff
– Immediate ack to source; handle failures asynchronously
– Celery autoretry_for=(Exception,), retry_backoff=True, retry_jitter=True, max_retries=6
– Dead-letter: mark status=dead and notify (Slack/Sentry) after final failure
Idempotency enforcement
– Unique index on (source, idempotency_key)
– For sources without idempotency header: derive key = sha256(sorted_json) or sha256(raw_body)
– In tasks, guard side effects with get_or_create patterns and transactional outbox
Performance tips
– Do not perform AI calls in request thread
– Use ujson/orjson for parsing; keep raw bytes for HMAC
– Gzip and HTTP/2 via Nginx/Cloudflare
– Limit inbound payload size (e.g., 1–5 MB) and archive large bodies
– Batch low-priority events in workers when possible
Security checklist
– Verify signatures before touching business logic
– Enforce IP allowlists where providers publish ranges (Stripe, Shopify)
– Use short time windows for timestamped signatures (e.g., 5 minutes)
– Store secrets in env/secret manager; rotate regularly
– TLS everywhere; HSTS at edge
– JWT between WordPress and Django; scope tokens to minimal perms
WordPress integration (status + actions)
Use WordPress as the operations console and result sink.
– Authentication to WP:
– Use Application Passwords or JWT plugin over HTTPS
– Endpoints:
– POST /wp-json/ai-gateway/v1/events/{id}/status
– POST /wp-json/ai-gateway/v1/results
– Capabilities:
– Map to custom post type “ai_event” with meta: source, event_type, status, attempts, last_error
– Admin list table for filtering errors and replays
WP plugin sketch (server-to-server)
– Register REST routes
– Validate Authorization: Bearer
– Capability checks for write operations
– On result POST, update ai_event post meta and optionally create a visible log entry
Example flow: Stripe invoice.created -> AI summary -> WP note
1) Stripe hits /api/hooks/stripe with invoice payload
2) Gateway verifies signature and enqueues task
3) Worker extracts line items and generates a bullet summary with an LLM
4) Worker POSTs to WordPress:
– /wp-json/ai-gateway/v1/results with {event_id, customer, summary, url}
5) WP stores the summary as a private note or custom post; admins see statuses in wp-admin
Anti-duplication at destination
– Use WP post meta unique key “ai_event_id” to prevent duplicate inserts
– For updates, use PUT/PATCH with If-Unmodified-Since to avoid races
Observability
– Correlation IDs: request_id propagated from ingress -> Celery -> WP
– Structured logs (JSON) with source, event_type, event_id, attempt
– Metrics: ingress count, verify failures, queue depth, task duration, success rate
– Tracing: OpenTelemetry for Django + Celery; sample rate tuned for cost
Deployment notes
– Nginx -> Gunicorn (Django) with keepalive and proxy_read_timeout 10s
– Concurrency: start with 2–4 Gunicorn workers; Celery workers sized by CPU-bound vs I/O-bound tasks
– Health checks: /healthz for app, Redis ping, DB readiness
– Webhook timeouts: keep handler under 200 ms; return 2xx even if downstream queued
– Blue/green or rolling deploys; drain Celery queues before shutdown
Minimal Django snippets (illustrative only)
Model constraint:
– UniqueConstraint(fields=[“source”, “idempotency_key”], name=“uq_source_idem”)
Celery task decorator:
– @shared_task(bind=True, autoretry_for=(Exception,), retry_backoff=True, retry_jitter=True, max_retries=6)
Safe WordPress POST (Python):
– session.post(wp_url, json=payload, headers={“Authorization”: f“Bearer {jwt}”}, timeout=10)
Hardening and data hygiene
– Validate JSON against Pydantic schemas per source; drop unexpected fields
– Mask PII in logs; encrypt archives at rest
– Rate limit abusive sources via Nginx and DRF throttling
– Add a replay endpoint secured to admins: POST /api/hooks/replay/{event_id}
What to build first (phased plan)
– Phase 1: Single source (Stripe), signature verify, idempotency, queue, basic worker, WP result sink
– Phase 2: Multi-source router, observability, retries/backoff, dead-letter handling
– Phase 3: Admin console (WP), replay tooling, payload archiving, tracing
– Phase 4: Performance tuning, batching, multi-region failover
This gateway pattern keeps external SLAs happy while your AI automations stay reliable, secure, and observable.
This is a fantastic reference architecture for a common and challenging problem; the emphasis on idempotency and a dedicated audit model is crucial. What is your preferred strategy for handling events that repeatedly fail and end up in a dead-letter state?
Thanks—agree that the “dead” path needs to be treated as a first-class workflow, not a dumping ground. When an event hits a dead-letter state in your setup, do you separate “retryable” vs “non-retryable” failures (e.g., 4xx validation vs upstream timeouts), and what retry/backoff policy do you use before declaring it dead? Also curious how you handle alerting and replay: is it manual via an admin view/CLI, or do you have tooling to requeue with safeguards (like rate limits and idempotency checks) so you don’t flood downstreams?
We use exponential backoff for retryable failures and an admin UI with rate-limiting for manual replays.
That makes sense. How do you draw the line between retryable vs non‑retryable in practice (HTTP status codes, exception types, or a per‑source policy), and what max attempts / backoff cap has worked well for you before you mark an event dead? Also, during admin replays, what safeguards do you rely on to avoid duplicate side effects—do you always reuse the original idempotency key, and do you replay in batches with any concurrency limits?
We generally classify 5xx errors as retryable for up to 10 attempts and reuse the original idempotency key for all manual replays to ensure safety.
That sounds like a solid baseline. How do you handle “in-between” cases like 429 rate limits (do you treat them as retryable with `Retry-After`, and is that policy per destination), and 408/connection timeouts/DNS hiccups—do those fall under the same 10-attempt budget or a separate network-error bucket? Also for admin replays, do you enforce any per-destination concurrency/ordering guarantees (e.g., one job per customer/workspace at a time) to avoid out-of-order side effects even when idempotency keys are reused?
We handle those transient errors with a separate, per-destination retry policy, and enforce per-customer ordering for admin replays to ensure safety.
Good approach. For the per-destination retry policy, do you honor `Retry-After` on 429s and add any jitter/backoff cap (max delay) so a single destination can’t stall the whole pipeline? And for the per-customer ordering during replays, what’s the mechanism you use in practice—queue routing/partitions per customer, a Redis/db lock, or a “single-flight” worker per key?
Yes, we honor `Retry-After` with capped, jittered backoff and use queue partitions per customer to ensure ordering.