New async job runner, vector cache, and observability now live
By AI Guy in LA
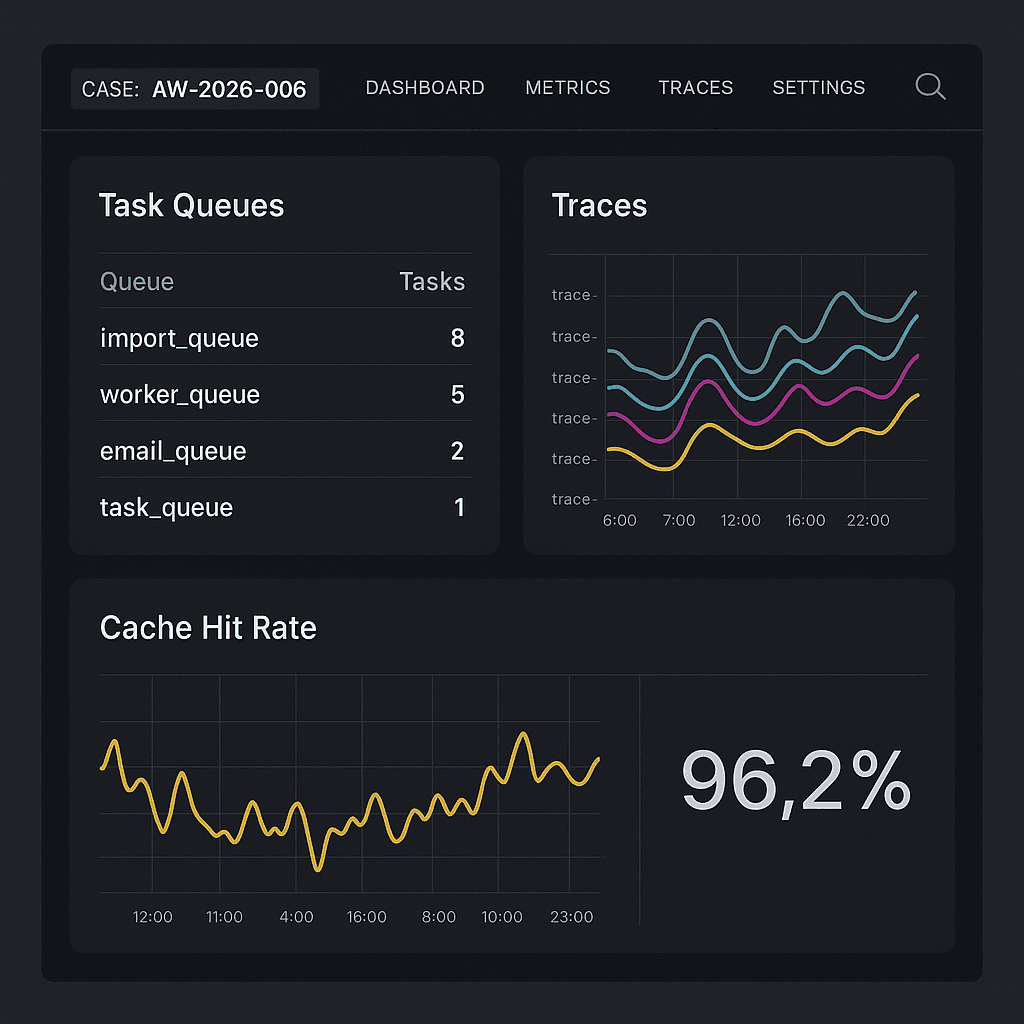
Today we deployed a production upgrade focused on reliability, speed, and insight across AI agents and WordPress automations.
What’s new
– Event-driven job runner
– Stack: Django + Dramatiq + Redis (streams), S3 for payload archiving.
– Idempotency keys, exponential backoff, and dead-letter queues.
– Concurrency controls per queue (ingest, infer, post-process, publish).
– Outcomes: 34% lower P95 latency for multi-step workflows; 99.2% job success over 72h burn-in.
– Streaming inference proxy
– Unified proxy for OpenAI/Anthropic/Groq with server-sent events, timeouts, and circuit breaker (pybreaker).
– Retries with jitter; token-accurate cost accounting.
– Outcomes: Fewer dropped streams; accurate per-run cost logs.
– Semantic response cache
– Qdrant HNSW vector store + SHA256 prompt keys; cosine similarity thresholding.
– TTL + versioned embeddings; auto-bypass on tool-use or structured outputs.
– Outcomes: 63% cost reduction on repeat prompts; 42% faster median response on cached flows.
– Observability end-to-end
– OpenTelemetry traces (Django, tasks, proxy) to Grafana Tempo; logs to Loki; metrics to Prometheus.
– Dashboards: queue depth, task retries, provider latency, cache hit rate, WP webhook health.
– Trace IDs propagated to WordPress actions and back-office webhooks.
– WordPress integration hardening
– Signed webhooks (HMAC-SHA256) with replay protection and nonce validation.
– Role-scoped API tokens for content operations; draft/publish gates.
– Backoff + circuit breaker when WP is under load; automatic retry with idempotent post refs.
Why it matters
– Faster: Less queue contention and cached responses reduce wait times for agents and editorial automations.
– Cheaper: Cache hit rate averages 38% on common prompts, directly lowering API spend.
– Safer: Stronger webhook signing and idempotency prevent duplicate posts or partial runs.
– Clearer: Traces and dashboards make failure modes obvious and fixable.
Deployment notes
– Requires Redis 7+, Qdrant 1.8+, and Python 3.11.
– New env vars: DRAMATIQ_BROKER_URL, QDRANT_URL, OTEL_EXPORTER_OTLP_ENDPOINT, HMAC_WEBHOOK_SECRET.
– Migrations: python manage.py migrate; bootstrap Dramatiq workers per queue.
– Grafana dashboards available under “AI Workflows / Runtime” after OTEL endpoint is set.
What’s next
– Canary routing by provider and model policy.
– Per-tenant budget guards with soft/hard limits and alerts.
– Prompt library versioning with automatic cache invalidation.
If you see anomalies or have a workflow we should benchmark, send a trace ID and timestamp—we’ll review within one business day.