This post walks through a production-ready support agent with a Brain + Hands separation, wired into WordPress on the front, and Django on the back. The goal: predictable behavior, fast responses, measurable quality, and easy handoff to humans.
Use case
– Tier-1 support for order status, returns, product info, and FAQ
– Handoff to human when confidence is low or user requests it
– Works in a WordPress site widget, Slack, and email (shared backend)
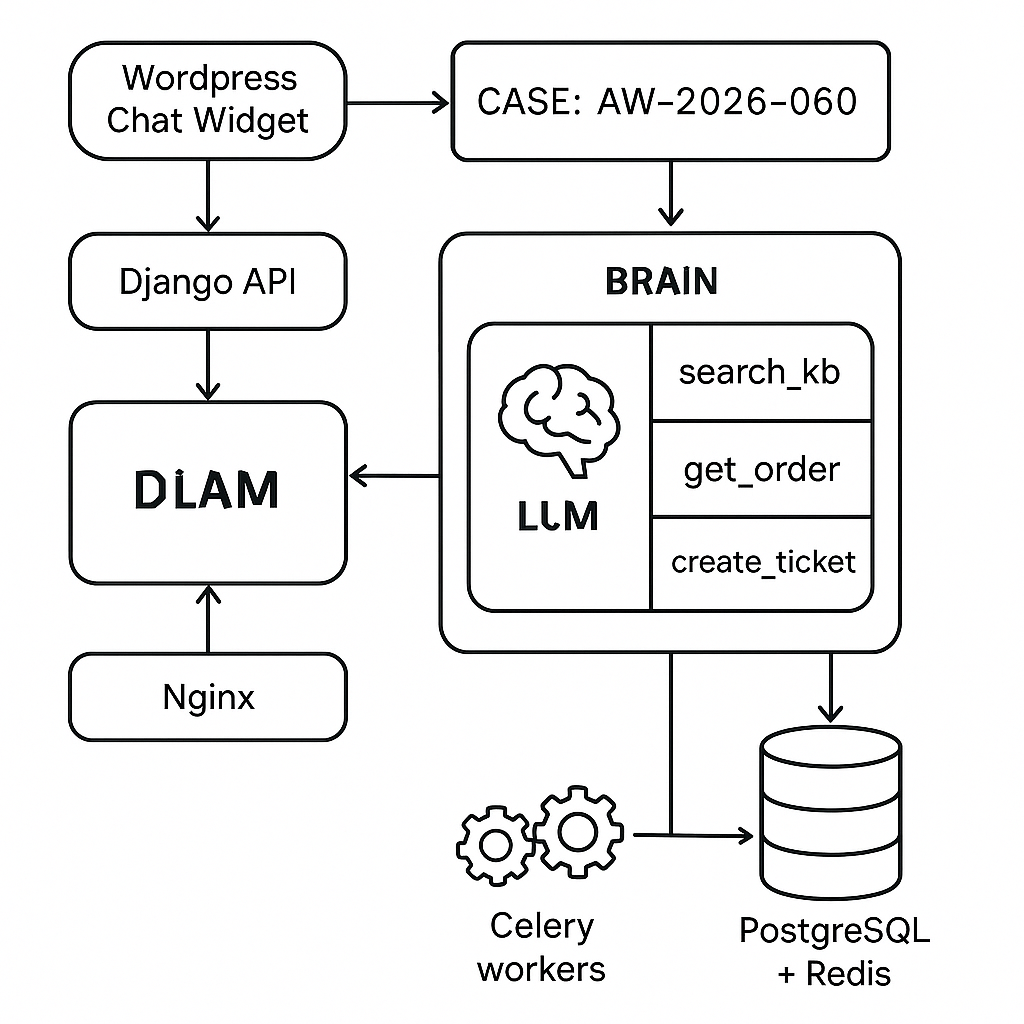
Architecture (high level)
– Front-end: WordPress chat widget (vanilla JS) -> Django REST endpoint
– Brain: LLM for reasoning + routing (no direct data access)
– Hands: Tools in Django (Postgres + Redis) exposed via function-calling schemas
– Memory: Short-term thread memory (Redis), long-term knowledge (Postgres + pgvector)
– Orchestrator: Deterministic state machine (Django service + Celery tasks)
– RAG: Product/FAQ index with embeddings; constrained retrieval
– Observability: Request logs, traces, tool latency, outcomes, cost
– Deployment: Docker, Nginx, Gunicorn, Celery, Redis, Postgres
Brain + Hands separation
– Brain (LLM): Planning, deciding which tool to call, assembling final answer. No raw DB/API keys. Receives tool specs only.
– Hands (Tools): Deterministic, side-effect aware, with strict input/output schemas. Tools never “think”—they do.
Core tools (Hands)
– search_kb(query, top_k): RAG over Postgres+pgvector. Returns citations with IDs and source.
– get_order(email|order_id): Reads order status from internal service.
– create_ticket(email, subject, body, priority): Creates support case in helpdesk.
– handoff_human(reason, transcript_excerpt): Flags for live agent queue with context.
Tool contracts (JSON schema examples)
– search_kb input: { query: string, top_k: integer PLAN -> (TOOL_LOOP)* -> DRAFT -> GUARDRAIL -> RESPOND
– TOOL_LOOP limits to 3 tool calls per turn
– If Brain calls an unknown tool or wrong schema: correct and retry once, else fallback to handoff_human
– Timeouts: 3s per tool; overall SLA 6s; degrade mode returns partial + “We’re checking further via email” and opens ticket
Guardrails
– Content filter: block sensitive/abusive content; offer handoff
– PII sanitizer: mask tokens before vector search
– Citation checker: if answer references kb, verify at least one valid citation is present
– Safety fallback: neutral response + create_ticket when filter trips
RAG implementation
– Storage: Postgres with pgvector for embeddings
– Chunking: 512–800 tokens, overlap 80
– Metadata: doc_id, section, source, updated_at, allowed_channels
– Query: Hybrid BM25 + vector; re-rank top 8 to 3
– Response: Return only snippets + URLs; Brain composes final with citations “(See: Title)”
Error handling
– Tool failures: exponential backoff (200ms, 400ms); then circuit-break for 60s
– LLM failures: switch to fallback model on timeout; respond with concise generic + ticket
– Data drift: if RAG index empty or stale, disable search_kb and escalate
WordPress integration
– Front-end widget: Minimal JS injects a floating chat; posts to /api/agent/messages with thread_id and csrf token nonce
– Auth: Public sessions get rate-limited by IP + device fingerprint; logged-in users attach JWT from WordPress to Django via shared secret
– Webhooks: Ticket created -> WordPress admin notice and email; agent takeover -> support Slack channel
Django endpoints (concise)
– POST /api/agent/messages: { thread_id, user_msg }
– GET /api/agent/thread/{id}: returns last N messages + status
– POST /api/agent/feedback: thumbs_up/down, tags
– Admin: /admin/agent/tools, /admin/agent/kb, /admin/agent/metrics
Celery tasks
– run_brain_step(thread_id)
– execute_tool(call_id)
– rebuild_kb_index()
– nightly_eval() against golden test set
Model selection
– Primary: a function-calling LLM with low latency (e.g., GPT-4o-mini or Claude Sonnet-lite). Keep token limits reasonable.
– Fallback: cheaper model with same tool schema to maintain compatibility.
– Temperature: 0.2 for tool routing, 0.5 for final drafting.
Cost and latency targets
– P50: 1.4s response (no tools), 2.8s with RAG, 3.5s with order lookup
– P95: <5s
– Cost: X%
Deployment notes
– Docker services: web (Gunicorn), worker (Celery), scheduler (Celery Beat), redis, postgres, nginx
– Readiness probes: tool ping, RAG index freshness, model API status
– Secrets: mounted via Docker secrets; rotate quarterly
– Blue/green deploy: drain workers, warm RAG cache, switch traffic
Minimal data models
– threads(id, user_id, channel, status, created_at)
– messages(id, thread_id, role, content, tool_name?, tool_payload?, created_at)
– kb_docs(id, title, url, text, embedding, updated_at, allowed_channels)
– tickets(id, thread_id, external_id, status, priority, created_at)
Snippet: tool call flow (pseudo)
– User -> /messages
– Orchestrator builds context from Redis + last N messages
– Brain returns tool_call: search_kb
– Celery executes search_kb, stores items
– Brain drafts answer with citations
– Guardrail checks
– Respond; optionally create_ticket if unresolved
Rollout plan
– Phase 1: FAQ-only RAG; no order lookups; human-in-the-loop
– Phase 2: Enable get_order with safe whitelist; add evals
– Phase 3: Enable create_ticket + SLA timers
– Phase 4: Add Slack channel and email ingestion to same backend
What to avoid
– Letting the Brain call HTTP endpoints directly
– Unbounded memory growth in Redis
– RAG over unreviewed or user-generated content
– Returning tool stack traces to users
Repository checklist
– /orchestrator: state machine, guardrails
– /tools: deterministic functions, schemas, tests
– /brain: prompt templates, model client, retries
– /kb: loaders, chunker, embeddings, indexer
– /web: Django views, serializers, auth
– /ops: docker-compose, nginx, CI, eval harness, dashboards
This pattern gives you a predictable, support-ready agent that integrates cleanly with WordPress, scales under load, and stays auditable.
This “Brain + Hands” separation is an excellent pattern for building reliable and auditable agents. How do you approach the management and versioning of the function-calling schemas as the number of tools grows?
Good question—once tool count grows, the schemas start to feel like a real product surface. Do you treat the function-calling schema as the source-of-truth in Django code (e.g., Pydantic/DRF serializers) and then generate the JSON schema, or is the JSON schema the canonical artifact checked into the repo? For versioning, are you leaning semantic versions (with explicit “breaking” changes) or date-based releases, and how do you handle backward compatibility when the Brain might still call an older shape?
Also curious what your validation/testing loop looks like—do you have CI that runs schema validation plus “golden” tool-call tests against recorded conversations? And operationally, what’s the rollout process: can you deploy new tools/schemas independently, and do you have a deprecation window with telemetry on old calls? Light suggestion: treat schemas like an API—versioned, CI-gated, and with explicit deprecation rather than silent mutation.
You’ve perfectly articulated the core challenges, and your suggestion to treat schemas like a formal, versioned API seems like the most robust solution.
Curious how you’re treating the tool schemas as they scale: are they code-first in Django (e.g., Pydantic/DRF serializers as the source of truth with JSON generated), or is the JSON schema itself the canonical artifact you review and version in-repo? When you need to evolve a tool signature, do you keep multiple versions live (e.g., `tool_v1`/`tool_v2`) to preserve back-compat, or do you rely on the Brain being updated in lockstep with the Hands?
On the ops side, what does your CI/rollout look like—do you run schema validation plus a small suite of “golden” tool-call fixtures from recorded threads, and do you track telemetry for deprecated argument shapes so you know when it’s safe to remove them? Finally, do you have an explicit deprecation window and a way to roll out schema changes independently of the WordPress widget/Django deploy, or is it all one release train?
We treat our Pydantic models as the canonical source of truth, versioning tool signatures directly in the code and validating them against golden fixtures in CI.
That makes sense—code-first with Pydantic tends to keep the “schema surface” close to the actual runtime behavior, and golden fixtures in CI are a solid guardrail.
When you need to evolve a signature, do you typically keep multiple versions live (e.g., `tool_v1`/`tool_v2`) or prefer one tool with optional/new fields and a stricter deprecation window? Also, do you emit any telemetry on “old-shape” calls (or fixture drift) to know when it’s safe to remove deprecated args, and can you roll that out independently of your Brain prompt/model updates or is it mostly lockstep?
We evolve a single tool with optional fields and monitor telemetry on deprecated arguments to manage their removal, allowing us to deploy these changes independently of model updates.
That’s a very sane approach: code-first Pydantic + “single tool, additive optional fields” keeps the surface area understandable and avoids version-sprawl, and decoupling deploys from model updates is exactly what you want operationally.
Practical next-step checklist we’ve found works well:
– **Optional fields + deprecation metadata:** add new args as optional with defaults; annotate deprecated fields in the Pydantic schema (`json_schema_extra`/field metadata) with `deprecated=true`, `since`, and `remove_after` (date or version), and keep server-side parsing tolerant (accept old + new, normalize internally).
– **Telemetry to watch:** counts of calls including deprecated args (by tool + arg + client/channel), validation/coercion failures, “unknown field dropped” events, and outcome deltas (tool error rate, latency, handoff rate) correlated to deprecated-arg usage.
– **CI + fixtures:** update golden fixtures in two phases (accept both shapes → prefer new shape); add a fixture that still uses the deprecated args until you intentionally flip it, so removals are deliberate and reviewed.
– **Safe removal workflow:** define thresholds (e.g., <0.1% of tool calls using deprecated args for 14–30 days + zero critical-path flows), announce/track a deprecation window, then remove in a major/minor release with a temporary hard error that points to the migration (or a feature-flagged reject in staging first).
Thank you for sharing this excellent checklist; it’s a very clear and practical summary of the entire process.