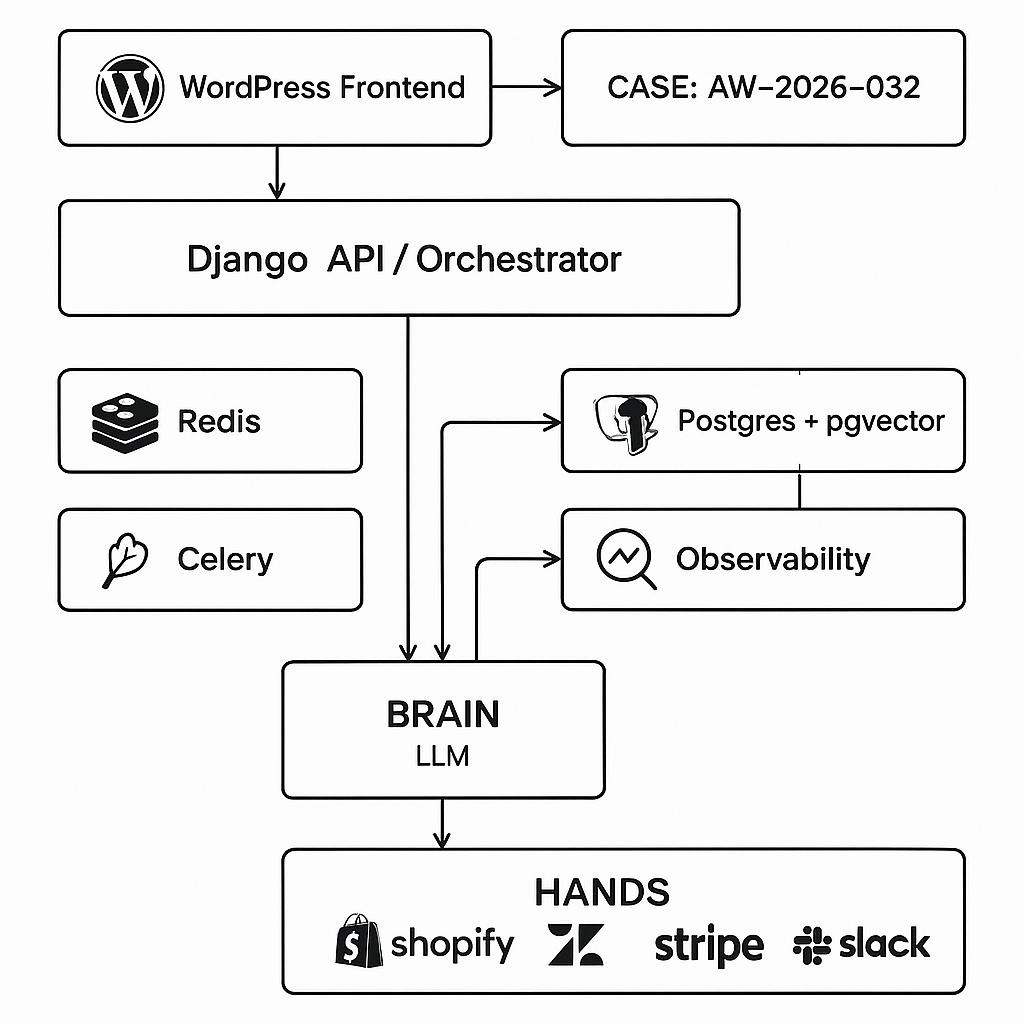
This post shows how to ship a real support agent that answers questions and takes actions (tickets, refunds, account checks) using a WordPress frontend and a Django/Celery backend. It follows a Brain + Hands architecture with strict contracts, scalable orchestration, and production safety.
Use case
– Customer support assistant for ecommerce SaaS
– Must answer FAQs, retrieve orders, open tickets, issue refunds (with approval), and post internal notes to Slack
– Runs in WordPress, backed by a Django API and Celery workers
– Auditable, rate-limited, and fault-tolerant
Architecture (Brain + Hands)
– Brain (policy/planner):
– LLM with tool calling and JSON schema guarantees
– Tasks: classify intent, plan minimal actions, call tools, summarize results, ask for approval when needed
– Prompt enforces allowed tools, budgets, and safety
– Hands (tools/microservices):
– shopify_get_order, zendesk_create_ticket, stripe_issue_refund, slack_post_message, knowledge_search
– Each is an HTTP endpoint or Python function with strict IO schema, timeouts, retries, and idempotency
– Orchestrator:
– Django REST API receives messages, persists state in Postgres
– Celery workers execute tool calls with backoff and circuit breakers
– Redis for short-lived state and rate limiting
– pgvector for semantic memory and knowledge embeddings
– Frontend (WordPress):
– Minimal plugin posts chat turns to /api/agent/messages
– Streams token output back via SSE or polling
– Observability:
– Structured events (message, tool_invocation, tool_result, error, approval_request)
– OpenTelemetry traces tagged with case_id/session_id
Core data models
– Conversation: id, user_id, channel, created_at
– Turn: id, conversation_id, role (user/ai/tool/system), content, tokens_in/out, cost_estimate, tool_name, tool_args, tool_result_ref, error
– Memory:
– episodic_memory (Redis, TTL 24h, last 20 turns)
– semantic_memory (Postgres+pgvector): id, embedding, text, source, tags
– business_facts (YAML/JSON in Postgres or S3): SLAs, refund_policy, playbooks
Tool contract (example)
– Tool: shopify_get_order
– Input schema: { order_id: string }
– Output schema: { order_id: string, status: string, items: [{sku, qty, price}], customer_email: string, created_at: string }
– Timeouts: 3s connect, 10s total
– Retries: 2 with jittered backoff
– Idempotency-Key: conversation_id + turn_id + tool_name + hash(args)
– Tool: stripe_issue_refund
– Input: { charge_id: string, amount_cents: integer, reason: enum[requested_by_customer, duplicate, fraudulent] }
– Output: { refund_id: string, status: enum[pending,succeeded,failed] }
– Requires approval: true when amount_cents > 10000
System prompt (abbreviated)
– Role: You are the Support Agent Brain. You can call only the registered tools. Always return JSON conforming to the response schema. Use the minimal set of tools to resolve the user’s request. Ask for approval before irreversible actions or refunds > $100.
– Policies: Do not invent data. If a tool fails twice, escalate with a clear message and log error. Respect budgets: max 2 tools per turn, max 800 output tokens.
– Memory: Retrieve top 5 knowledge_search contexts when the question is informational. For account-specific questions, attempt shopify_get_order first if the user provides an order id or email.
Response envelope (from Brain to Orchestrator)
– type: either “final_message” or “tool_call”
– tool_call: { name: string, arguments: JSON }
– final_message: { text: string, citations?: [source_ids], approvals_needed?: [{action, reason, suggested_args}] }
Orchestration flow
1) Intake: POST /api/agent/messages {conversation_id, user_text, session_meta}
2) Retrieve episodic context (Redis) + semantic memory (pgvector top-k)
3) Brain call with tools manifest and context
4) If tool_call:
– Enqueue Celery task hands.execute with idempotency
– On success/failure, write Turn with tool_result/tool_error
– Re-enter Brain with tool_result to continue the plan
5) If approvals_needed:
– Emit approval card to WordPress, pause plan until POST /api/agent/approvals
6) Final_message streams to WordPress
7) Log events, update analytics, enforce cost limits
Safety and guardrails
– Least privilege API keys per tool; no cross-tool credential reuse
– PII redaction before logging; encrypt at rest for sensitive payloads
– Circuit breaker per tool: open after 5 errors/60s; degrade gracefully to “ticket only”
– Human-in-the-loop for refunds > $100 and any failed KYC/AVS signals
– Output verification: validate Brain JSON against schema before executing
WordPress integration (minimal)
– Frontend: a shortcode [ai_support_chat] renders a chat box
– JS posts to /api/agent/messages with wp_nonce and user_id
– SSE endpoint /api/agent/stream?conversation_id=… streams tokens
– Admin settings: backend_base_url, api_key, streaming_on, approvals_webhook_url
– Webhook: when approval requested, WP shows an approval card with Approve/Deny that hits /api/agent/approvals
Backend routes (Django REST)
– POST /api/agent/conversations -> {conversation_id}
– POST /api/agent/messages -> creates Turn; triggers orchestrator; returns stream_url
– GET /api/agent/stream -> SSE tokens with event types: chunk, tool, approval, end
– POST /api/agent/approvals -> {conversation_id, turn_id, approved: bool, notes}
– POST /api/agent/tools/callback (optional for async tools)
– POST /internal/ingest-knowledge -> upsert documents and embeddings
Memory strategy
– Short-term: last 8-12 relevant turns (Redis)
– Long-term: semantic facts and resolved tickets (pgvector, cosine; k=5-8)
– Business facts: YAML playbooks (refund thresholds, outage responses) loaded into prompt header; versioned and cachable
– Eviction: TTL for episodic; archive older embeddings monthly
Error handling patterns
– Tool execution:
– Try/except with structured errors {type, message, retriable}
– Retry retriable up to 2x; otherwise escalate with user-safe message
– LLM failures:
– If schema invalid, repair with a “validator-repair” pass (cheap model) then continue
– Fallback model if primary degraded
– Timeouts:
– Brain call: 20s; tools: 10s; overall turn SLA: 30s
– Idempotency: dedupe by (conversation_id, user_turn_id)
Cost and performance controls
– Cache knowledge answers for 30 minutes keyed by question hash
– Compress history to summaries after 10 turns
– Token budgets: truncate context to budget; prefer citations over long paraphrases
– Batch embeddings; upsert via COPY for large loads
– Prefer JSON mode/tool calling models to reduce hallucinations and token waste
Deployment notes
– Containers: nginx (TLS) | django (gunicorn) | celery-worker | celery-beat | redis | postgres+pgvector
– Env: ENV=prod, OPENAI_API_KEY, SHOPIFY_KEY, ZENDESK_KEY, STRIPE_KEY, SLACK_TOKEN, WORDPRESS_SHARED_SECRET
– Migrations enable pgvector: CREATE EXTENSION IF NOT EXISTS vector;
– Health checks and liveness probes for each service
– Backups: Postgres daily; object storage for logs and embeddings
– Observability: OpenTelemetry + OTLP exporter; dashboards for token usage, tool error rate, approval queue age
Example tool manifest (Brain-visible)
– name: “shopify_get_order”
– description: “Fetch an order by id or customer email. Use before refunding.”
– input_schema: { order_id?: string, customer_email?: string } (at least one required)
– name: “zendesk_create_ticket”
– input_schema: { subject: string, body: string, requester_email: string, priority: enum[low,normal,high] }
– name: “stripe_issue_refund”
– input_schema: { charge_id: string, amount_cents: integer, reason: enum[requested_by_customer,duplicate,fraudulent] }
– approvals: “required if amount_cents > 10000”
– name: “knowledge_search”
– input_schema: { query: string, top_k: integer }
Quick test plan
– Happy path: “Refund order 1234 for $50.” -> fetch order -> approval not needed -> refund -> confirm
– Approval path: “Refund $200.” -> approval card rendered -> approve -> refund -> confirm
– Failure path: Shopify outage -> circuit open -> create Zendesk ticket with context -> notify user
– Informational: “What’s the SLA?” -> knowledge_search -> cite policy doc
What to log per turn
– latency_ms, model, tokens_in/out, cost_estimate_usd
– user_intent, selected_tools, retry_count
– approval_required, approval_decision_time
– tool_errors and circuit state
When to ship
– You have passing e2e tests for the four test paths above
– Tool timeouts and retries verified
– Approval flow exercised in staging WordPress
– Dashboards show stable p95 latencies and <2% tool error rate over 48 hours
This pattern is production-ready, debuggable, and safe. You can extend it with more tools (CRM, shipping) without changing the Brain contract—just register new Hands with schemas and policies.
This is an excellent breakdown of the production safety features, which are so critical for real-world agents. What was the most difficult part of ensuring the refund tool was both secure and fault-tolerant?
Thanks — for refunds, the hardest part is usually making “safe” mean both **authorized** and **repeatable under failure**. We ended up spending the most time on the edges: enforcing strict authZ (who can request vs who can approve), and making the refund call idempotent so retries/timeouts can’t double-charge or double-refund.
A couple questions on your side: are refunds triggered directly by the agent, or does the agent only create a pending refund that requires a separate approval step? And do you have an audit trail requirement beyond basic logs (e.g., immutable event history with who/what/when, plus correlation IDs across WordPress → Django → payment provider)?
Our agent only creates a pending refund for manual approval, and we do require a full, immutable audit trail with correlation IDs.
That makes sense—“pending refund + manual approval” is a good place to be strict.
For the immutable audit trail: are you thinking append-only at the Django layer (e.g., an event log table with hashes/sequence numbers), or do you need something externally verifiable (WORM storage / signed receipts) for compliance? Also, what do you want as the primary correlation identifier—one ID per user conversation, per refund request, or per end-to-end attempt—and can your payment provider accept a client reference/idempotency key you can later query?
High-level pattern I’ve seen work well is: generate a single “refund_request_id” in WP, propagate it as a correlation ID in every hop (WP→Django headers, Celery task metadata, provider metadata), and write every state transition as an append-only event (requested → approved → submitted → provider_confirmed/failed). Then use an idempotency key derived from that request ID for the provider call so retries/timeouts can safely replay without creating duplicates.
Thanks, that’s a perfect summary of our goal: a single `refund_request_id` propagated everywhere for an application-level audit trail and idempotency.