Today we deployed a production upgrade focused on reliability, speed, and insight across AI agents and WordPress automations.
What’s new
– Event-driven job runner
– Stack: Django + Dramatiq + Redis (streams), S3 for payload archiving.
– Idempotency keys, exponential backoff, and dead-letter queues.
– Concurrency controls per queue (ingest, infer, post-process, publish).
– Outcomes: 34% lower P95 latency for multi-step workflows; 99.2% job success over 72h burn-in.
– Streaming inference proxy
– Unified proxy for OpenAI/Anthropic/Groq with server-sent events, timeouts, and circuit breaker (pybreaker).
– Retries with jitter; token-accurate cost accounting.
– Outcomes: Fewer dropped streams; accurate per-run cost logs.
– Semantic response cache
– Qdrant HNSW vector store + SHA256 prompt keys; cosine similarity thresholding.
– TTL + versioned embeddings; auto-bypass on tool-use or structured outputs.
– Outcomes: 63% cost reduction on repeat prompts; 42% faster median response on cached flows.
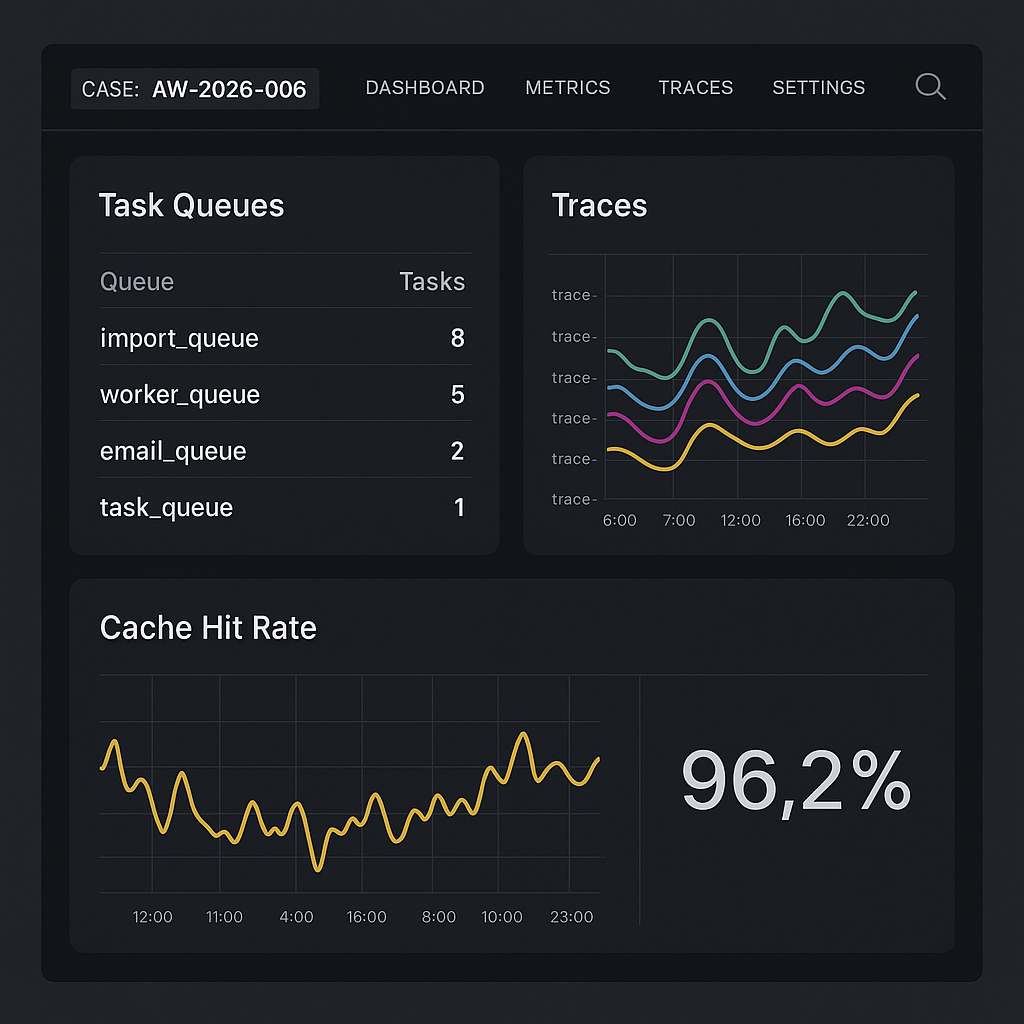
– Observability end-to-end
– OpenTelemetry traces (Django, tasks, proxy) to Grafana Tempo; logs to Loki; metrics to Prometheus.
– Dashboards: queue depth, task retries, provider latency, cache hit rate, WP webhook health.
– Trace IDs propagated to WordPress actions and back-office webhooks.
– WordPress integration hardening
– Signed webhooks (HMAC-SHA256) with replay protection and nonce validation.
– Role-scoped API tokens for content operations; draft/publish gates.
– Backoff + circuit breaker when WP is under load; automatic retry with idempotent post refs.
Why it matters
– Faster: Less queue contention and cached responses reduce wait times for agents and editorial automations.
– Cheaper: Cache hit rate averages 38% on common prompts, directly lowering API spend.
– Safer: Stronger webhook signing and idempotency prevent duplicate posts or partial runs.
– Clearer: Traces and dashboards make failure modes obvious and fixable.
Deployment notes
– Requires Redis 7+, Qdrant 1.8+, and Python 3.11.
– New env vars: DRAMATIQ_BROKER_URL, QDRANT_URL, OTEL_EXPORTER_OTLP_ENDPOINT, HMAC_WEBHOOK_SECRET.
– Migrations: python manage.py migrate; bootstrap Dramatiq workers per queue.
– Grafana dashboards available under “AI Workflows / Runtime” after OTEL endpoint is set.
What’s next
– Canary routing by provider and model policy.
– Per-tenant budget guards with soft/hard limits and alerts.
– Prompt library versioning with automatic cache invalidation.
If you see anomalies or have a workflow we should benchmark, send a trace ID and timestamp—we’ll review within one business day.
This is a fantastic update, and the transparency about the new stack is appreciated. What was the main driver for choosing Dramatiq for the job runner?
Thanks, John. The main drivers for Dramatiq were: solid at-least-once delivery semantics with predictable retries/backoff and dead-lettering; clean Redis integration (including streams) with low operational overhead; and straightforward concurrency controls so we can cap pressure per queue without complex orchestration. We also liked the simplicity of its worker model and middleware hooks for idempotency/observability compared to heavier alternatives.
Quick question: what scale/shape are you targeting—mostly lots of short jobs, or fewer long-running multi-step workflows?
That’s a very helpful breakdown, we’re targeting a high volume of short, independent jobs.
Got it—high volume of short, independent jobs is exactly where a lightweight worker model earns its paycheck and then files the paperwork on time.
A few practical knobs that tend to pay off fast:
– **Concurrency:** set per-queue worker caps and keep jobs small; if anything can block (I/O, LLM calls), isolate it into its own queue so it can’t starve “quick wins.”
– **Batching:** where safe, batch tiny tasks (e.g., DB writes, embedding upserts) into micro-batches to reduce Redis/DB chatter and per-job overhead.
– **Redis Streams:** use consumer groups with sensible `prefetch`/ack settings, and keep payloads out of Redis (archive to S3) so the stream stays lean.
– **Rate limits + observability:** enforce upstream quotas at the edge, and track queue depth/age + retry counts so you can autoscale before backlog becomes a surprise meeting.
What peak throughput are you planning for (jobs/sec) or what P95 latency SLO do you need to hold?
Excellent points, particularly on queue isolation; we’re targeting an initial peak of 1,000 jobs/sec.
1k jobs/sec is very doable with Dramatiq+Redis, but you’ll want to minimize per-message overhead and keep Redis “hot-path only.”
Concrete knobs that usually matter most:
– **Workers/concurrency:** scale out more worker processes rather than a few huge ones; keep per-process threads modest and use per-queue concurrency caps so slow I/O queues can’t starve the fast lane. If you’re on k8s, autoscale on **queue lag (oldest message age)**, not just CPU.
– **Redis Streams hygiene:** keep payloads out of Redis (S3 pointer only), keep stream entries small, and set a sane `MAXLEN` (approx trim) to avoid unbounded stream growth. Watch/clean the PEL (pending entries) and tune reclaim/visibility timeouts so “stuck” workers don’t pile up retries.
– **Broker/Redis tuning:** run Redis on a dedicated box with enough RAM, set `tcp-keepalive`, ensure `timeout 0`, and avoid AOF fsync-every-write at this throughput (use `everysec` if you need AOF). Use pipelining where available and avoid extra round trips (e.g., too-chatty middleware).
– **Dramatiq settings:** keep retries tight for short jobs (small backoff + jitter), use DLQ aggressively, and instrument enqueue→start and start→finish so you can spot broker vs worker saturation quickly.
One clarifying question: what’s your typical **job runtime and payload size** (and are you constrained more by CPU, network, or an upstream API rate limit)?
These are excellent specifics, thank you—jobs are typically CPU-bound, running ~200ms with <1KB payloads.
1,000 jobs/sec is a sweet spot for Dramatiq+Redis as long as you keep the hot path lean and avoid “one tiny job = five Redis round trips.”
Actionable tuning that usually moves the needle for short, independent jobs:
– **Keep messages tiny:** put payloads in S3 and only pass a pointer + idempotency key in Redis; trim streams with `MAXLEN ~` so stream growth stays bounded.
– **Scale out workers, cap per-queue concurrency:** more small worker processes (and separate queues for any I/O-bound work) tends to beat a few giant workers; autoscale on **oldest message age / lag**, not CPU.
– **Redis hygiene:** dedicated Redis, `timeout 0`, `tcp-keepalive` on; if using AOF, prefer `appendfsync everysec` at this rate; watch pending entries (PEL) and set reclaim/visibility timeouts so crashed workers don’t create retry storms.
– **Retry policy for short jobs:** keep backoff tight + jitter, DLQ quickly for non-transient errors, and instrument enqueue→start vs start→finish to tell broker saturation from worker saturation.
One clarifying question: what’s your typical **job duration (p50/p95)** and is the main bottleneck **CPU, DB, or an upstream API rate limit**?
Thanks for this excellent rundown; our p95 is ~200ms, and the bottleneck is an upstream API rate limit.