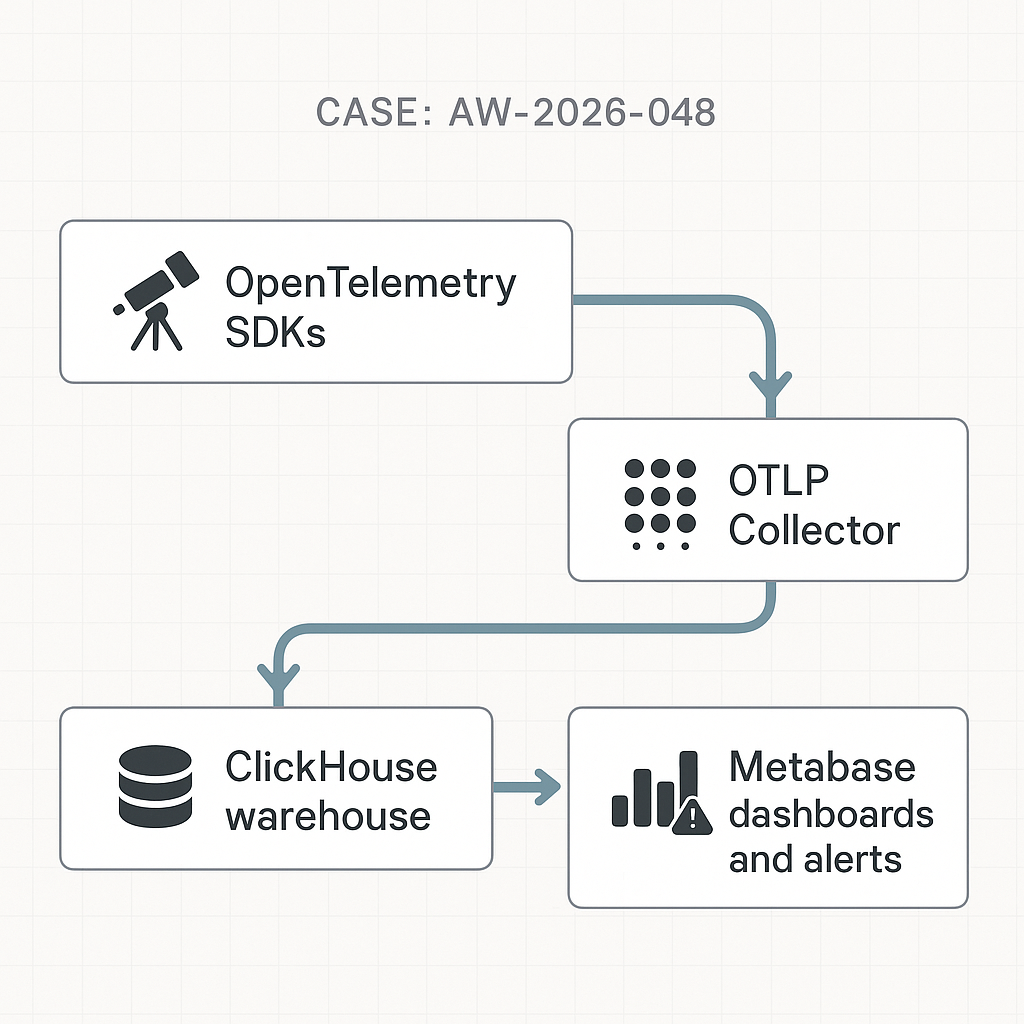
Goal
– Track agent runs, tool calls, latency, errors, tokens, and costs with second-level freshness.
– Keep ingestion cheap, queries fast, and schema stable as features evolve.
Reference architecture (text)
– Clients (agents, workers, webhooks) → OpenTelemetry SDK → OTLP HTTP → OpenTelemetry Collector → ClickHouse (native) → Metabase dashboards and alerts.
– Optional: Kafka between Collector and ClickHouse for burst smoothing.
Data model (minimally sufficient, append-only)
– events
– event_id (UUID)
– ts (DateTime64)
– app (String)
– env (Enum: prod, staging)
– run_id (UUID)
– type (Enum: run_started, run_finished, tool_call, error, token_usage)
– agent (String)
– user_id (String or UUID nullable)
– status (Enum: ok, error, timeout nullable)
– latency_ms (UInt32 nullable)
– tokens_prompt, tokens_completion (UInt32 nullable)
– cost_usd (Decimal(12,6) nullable)
– meta (JSON)
ClickHouse DDL
CREATE TABLE events
(
event_id UUID,
ts DateTime64(3, ‘UTC’),
app LowCardinality(String),
env Enum8(‘prod’ = 1, ‘staging’ = 2),
run_id UUID,
type LowCardinality(String),
agent LowCardinality(String),
user_id String,
status LowCardinality(String),
latency_ms UInt32,
tokens_prompt UInt32,
tokens_completion UInt32,
cost_usd Decimal(12,6),
meta JSON
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(ts)
ORDER BY (app, env, agent, ts)
TTL ts + INTERVAL 90 DAY DELETE
SETTINGS index_granularity = 8192;
Materialized views (rollups for fast dashboards)
CREATE MATERIALIZED VIEW mv_runs_hour
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(dt)
ORDER BY (app, env, agent, dt)
AS
SELECT
app, env, agent,
toStartOfHour(ts) AS dt,
countIf(type = ‘run_finished’) AS runs,
countIf(status = ‘error’) AS errors,
sumIf(latency_ms, type = ‘run_finished’) AS p50_proxy, — use quantiles below for real pXX
sum(tokens_prompt) AS tokens_prompt,
sum(tokens_completion) AS tokens_completion,
sum(cost_usd) AS cost_usd
FROM events
GROUP BY app, env, agent, dt;
For real latency percentiles, use AggregatingMergeTree with quantileState/quantileMerge:
– Store quantileState(0.5), (0.9), (0.99) and merge in queries.
Ingestion via OpenTelemetry Collector
otel-collector.yaml (core)
receivers:
otlp:
protocols:
http:
endpoint: 0.0.0.0:4318
exporters:
clickhouse:
endpoint: tcp://clickhouse:9000
database: default
logs_table_name: events
ttl: 90d
processors:
batch:
timeout: 1s
send_batch_size: 4096
service:
pipelines:
logs:
receivers: [otlp]
processors: [batch]
exporters: [clickhouse]
Note: We treat all telemetry as “logs” with structured bodies to keep one table. If you need traces, add traces pipeline and derive events via processors.
Python instrumentation (FastAPI worker)
from opentelemetry import trace, metrics
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.exporter.otlp.proto.http._log_exporter import OTLPLogExporter
import logging, time, uuid, os, json
OTLP_ENDPOINT = os.getenv(“OTLP_HTTP”, “http://otel-collector:4318”)
# Logs as events
lp = LoggerProvider(resource=Resource.create({“service.name”:”agent-service”,”env”:”prod”}))
log_exporter = OTLPLogExporter(endpoint=f”{OTLP_ENDPOINT}/v1/logs”)
lp.add_log_record_processor(BatchSpanProcessor(log_exporter)) # SDK versions may use BatchLogRecordProcessor
logger = logging.getLogger(“ai-agent”)
logger.setLevel(logging.INFO)
logger.addHandler(LoggingHandler(level=logging.INFO, logger_provider=lp))
def emit_event(payload: dict):
logger.info(json.dumps(payload))
def run_agent(agent, user_id, prompt_tokens, completion_tokens, cost):
run_id = str(uuid.uuid4())
t0 = time.time()
emit_event({
“type”:”run_started”,”run_id”:run_id,”agent”:agent,
“app”:”myapp”,”env”:”prod”,”ts”:int(time.time()*1000)
})
try:
# … do work …
latency = int((time.time()-t0)*1000)
emit_event({
“type”:”run_finished”,”run_id”:run_id,”agent”:agent,
“status”:”ok”,”latency_ms”:latency,
“tokens_prompt”:prompt_tokens,
“tokens_completion”:completion_tokens,
“cost_usd”:float(cost),
“app”:”myapp”,”env”:”prod”,”ts”:int(time.time()*1000)
})
except Exception as e:
emit_event({
“type”:”error”,”run_id”:run_id,”agent”:agent,
“status”:”error”,”error_msg”:str(e),
“app”:”myapp”,”env”:”prod”,”ts”:int(time.time()*1000)
})
Node.js instrumentation (workers or Next.js routes)
import pino from ‘pino’
import { logs } from ‘@opentelemetry/api-logs’
import { LoggerProvider } from ‘@opentelemetry/sdk-logs’
import { OTLPLogExporter } from ‘@opentelemetry/exporter-logs-otlp-http’
const provider = new LoggerProvider()
provider.addLogRecordProcessor(new (require(‘@opentelemetry/sdk-logs’).BatchLogRecordProcessor)(
new OTLPLogExporter({ url: process.env.OTLP_HTTP + ‘/v1/logs’ })
))
logs.setGlobalLoggerProvider(provider)
const log = pino()
function emit(payload) { log.info(payload) }
emit({ type:’tool_call’, agent:’router’, run_id:’…’, latency_ms:32, app:’myapp’, env:’prod’, ts: Date.now() })
Metabase setup
– Connect to ClickHouse via the official driver.
– Mark events.ts as Time field. Create model views for:
– Runs by agent, environment
– Error rate by hour (countIf/status)
– P50/P90/P99 latency using quantile functions
– Token and cost per run, per user, per agent
– Parameterize app, env, agent to reuse dashboards across services.
Example SQL (Metabase card: error rate, last 24h)
SELECT
toStartOfMinute(ts) AS minute,
countIf(type = ‘run_finished’) AS runs,
countIf(status = ‘error’) AS errors,
(errors / nullIf(runs,0)) AS error_rate
FROM events
WHERE app = {{app}} AND env = {{env}} AND ts >= now() – INTERVAL 24 HOUR
GROUP BY minute
ORDER BY minute;
Alerts (Metabase → webhook/Slack)
– Threshold: error_rate > 0.05 for 5+ minutes
– Latency SLO breach: quantile(0.9)(latency_ms) > 2000 over last 15 minutes
– Cost guardrail: sum(cost_usd) > {{budget}} per day per agent
Backfill and idempotency
– If upstream replays, use event_id to dedupe:
CREATE TABLE events_dedup AS events ENGINE = ReplacingMergeTree(event_id)
…then insert into events_dedup and read from a view.
– For batch imports, use clickhouse-client with CSV/JSONEachRow. Preserve event_id.
Performance notes
– Aim for ≤1s collector batch timeout, 4–8k batch size.
– Keep meta JSON small and shallow. Move hot keys to top-level columns.
– Partition monthly, order by (app, env, agent, ts) for common filters.
– Prefer materialized aggregates for PXX latency and daily costs to keep dashboard queries <200ms.
Cost control
– TTL 90d raw, 365d for hourly aggregates.
– Compress with ZSTD; default is fine. Expect low storage/GB for numeric columns.
– Use Metabase cache 5–15 minutes on heavy cards.
Security and compliance
– Do not log PII. If needed, hash user_id and store mapping in a separate service.
– Enforce network policies: Collector and ClickHouse behind private network; Metabase via SSO.
– Rotate ClickHouse users; use readonly for BI.
Deployment tips
– Docker compose three services minimum: clickhouse, otel-collector, metabase.
– Health checks: Collector /healthz, ClickHouse system.metrics, Metabase /api/health.
– Sizing starter: 2 vCPU, 8GB RAM ClickHouse; 1 vCPU, 1GB Collector; 2 vCPU, 4GB Metabase. Scale storage IOPS first.
What to track next
– Tool-level success rate and latency
– Vendor breakdown (OpenAI, Anthropic, local) for spend and tokens
– Guardrails: rejection reasons, safe-output hits
– Queue metrics (depth, lag) for throughput planning
Summary
This stack ships real-time, production-grade observability for AI agents with minimal overhead. Start with OTLP → Collector → ClickHouse → Metabase, add materialized rollups for speed, and wire alerts to keep latency, reliability, and cost within SLOs.