Why this matters
Webhook-driven automations are the backbone for AI systems that react to events (content updates, CRM changes, user actions). In production, you need signature verification, idempotency, queuing, retries, and observability. Below is a deployable pattern using WordPress → Django (DRF) → Celery → AWS SQS/SNS with clear security and performance choices.
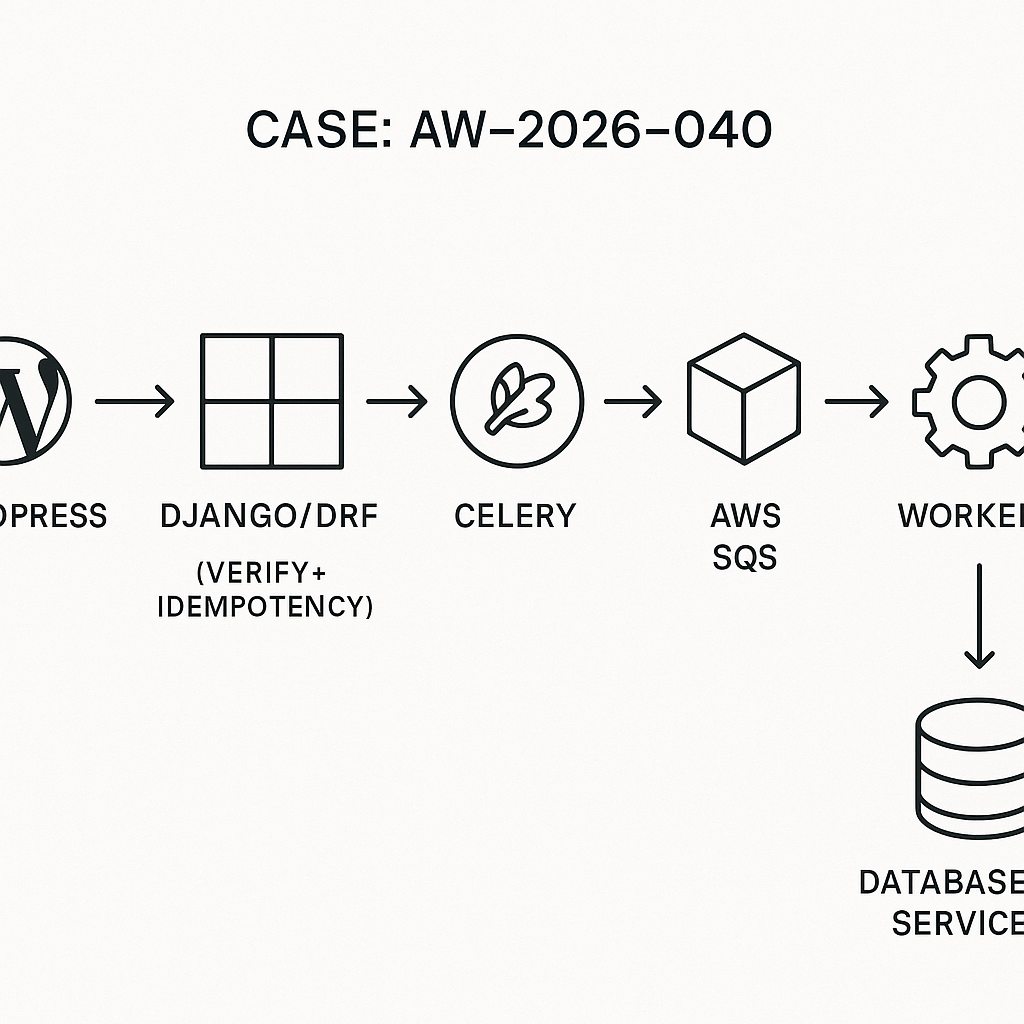
Reference architecture
– Producers: WordPress, Stripe, HubSpot, Slack (any external)
– Edge: API Gateway or Nginx (rate limiting, TLS, request size caps)
– Ingestion: Django REST Framework endpoint (signature verify, validate, idempotency)
– Queue: Celery + AWS SQS (main queue) + DLQ
– Workers: Celery tasks (AI calls, DB updates, API fan-out)
– Storage: Postgres (events, idempotency, payload store)
– Observability: Structured logs, request tracing, metrics, Sentry
Security fundamentals
– Transport: TLS everywhere. If internal, still terminate TLS at gateway.
– AuthN/AuthZ (choose one, don’t mix casually):
– HMAC signatures (per-integration secret; rotate quarterly).
– JWT with short expiration and kid-based key rotation.
– mTLS for high-trust peers.
– Signature header convention:
– X-Signature: scheme=v1,ts=unix,hash=hex(hmac_sha256(secret, ts + “.” + body))
– Enforce a 5-minute timestamp window and single-use idempotency keys.
Idempotency and replay protection
– Require X-Idempotency-Key (UUIDv4 from producer).
– Store a hash of (producer, key, body_hash). Return 200 with stored result on duplicates.
– Never depend on provider delivery guarantees; your layer must be safe-to-retry.
Example Django models (Postgres)
– Event table (raw payload + minimal indexable fields)
– Idempotency table
Python (models.py)
from django.db import models
class WebhookEvent(models.Model):
source = models.CharField(max_length=64, db_index=True)
event_type = models.CharField(max_length=128, db_index=True)
external_id = models.CharField(max_length=128, null=True, blank=True, db_index=True)
idempotency_key = models.CharField(max_length=64, db_index=True)
received_at = models.DateTimeField(auto_now_add=True, db_index=True)
payload = models.JSONField()
status = models.CharField(max_length=32, default=”queued”, db_index=True)
processing_attempts = models.IntegerField(default=0)
last_error = models.TextField(null=True, blank=True)
class IdempotencyKey(models.Model):
source = models.CharField(max_length=64)
key = models.CharField(max_length=64)
body_hash = models.CharField(max_length=64)
created_at = models.DateTimeField(auto_now_add=True)
class Meta:
unique_together = (“source”, “key”)
Signature verification (HMAC)
Python (security.py)
import hmac, hashlib, time
def compute_sig(secret: str, ts: str, body: bytes) -> str:
msg = f”{ts}.”.encode() + body
return hmac.new(secret.encode(), msg, hashlib.sha256).hexdigest()
def verify_sig(secret: str, ts: str, body: bytes, provided: str, skew_sec=300):
now = int(time.time())
if abs(now – int(ts)) > skew_sec:
return False
expected = compute_sig(secret, ts, body)
return hmac.compare_digest(expected, provided)
Django DRF endpoint
– Validates headers: X-Source, X-Idempotency-Key, X-Timestamp, X-Signature
– Verifies HMAC
– Upserts IdempotencyKey
– Persists WebhookEvent
– Enqueues Celery task with event id
Python (views.py)
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from django.db import transaction, IntegrityError
from django.utils.crypto import salted_hmac
from .models import WebhookEvent, IdempotencyKey
from .security import verify_sig
import hashlib, json
from .tasks import process_event
SECRETS = {“wordpress”: “wp_shared_secret”, “hubspot”: “hs_secret”} # store in env/secret manager
class IngestWebhook(APIView):
authentication_classes = []
permission_classes = []
def post(self, request):
src = request.headers.get(“X-Source”)
idem = request.headers.get(“X-Idempotency-Key”)
ts = request.headers.get(“X-Timestamp”)
sig = request.headers.get(“X-Signature”)
if not all([src, idem, ts, sig]) or src not in SECRETS:
return Response(status=status.HTTP_400_BAD_REQUEST)
raw = request.body
if not verify_sig(SECRETS[src], ts, raw, sig):
return Response(status=status.HTTP_401_UNAUTHORIZED)
payload = request.data
body_hash = hashlib.sha256(raw).hexdigest()
try:
with transaction.atomic():
IdempotencyKey.objects.create(source=src, key=idem, body_hash=body_hash)
evt = WebhookEvent.objects.create(
source=src,
event_type=str(payload.get(“type”) or payload.get(“event”)),
external_id=str(payload.get(“id”) or “”),
idempotency_key=idem,
payload=payload,
)
except IntegrityError:
# Duplicate: fetch existing and return 200
return Response({“status”: “duplicate”}, status=status.HTTP_200_OK)
process_event.delay(evt.id)
return Response({“status”: “queued”}, status=status.HTTP_202_ACCEPTED)
Celery + AWS SQS
– Use SQS Standard queue for throughput; attach DLQ with redrive policy (e.g., maxReceiveCount=5).
– Configure Celery broker: sqs:// with boto3 credentials from IAM role (no inline keys).
Python (celery.py)
import os
from celery import Celery
app = Celery(“ai_automation”)
app.conf.broker_url = “sqs://”
app.conf.task_default_queue = “ingest-events”
app.conf.broker_transport_options = {
“region”: os.getenv(“AWS_REGION”, “us-west-2”),
“visibility_timeout”: 300,
“polling_interval”: 1,
}
app.conf.task_acks_late = True
app.conf.task_time_limit = 240
app.conf.worker_max_tasks_per_child = 1000
Celery task with retries and DLQ handoff
Python (tasks.py)
from .models import WebhookEvent
from .celery import app
import backoff, logging
log = logging.getLogger(__name__)
@app.task(bind=True, autoretry_for=(Exception,), retry_backoff=True, retry_backoff_max=60, retry_kwargs={“max_retries”: 5})
def process_event(self, event_id: int):
evt = WebhookEvent.objects.get(id=event_id)
try:
# Route by source and type
if evt.source == “wordpress” and evt.event_type == “post.updated”:
handle_wordpress_post(evt.payload)
elif evt.source == “hubspot”:
handle_hubspot_event(evt.payload)
else:
handle_generic(evt.payload)
evt.status = “done”
evt.save(update_fields=[“status”])
except Exception as e:
evt.processing_attempts += 1
evt.last_error = str(e)[:2000]
evt.status = “error”
evt.save(update_fields=[“processing_attempts”, “last_error”, “status”])
raise
WordPress → Signed webhook on post update
– Trigger on save_post to send minimal payload.
– Store shared secret in wp-config.php (e.g., AI_BRIDGE_SECRET).
– Use wp_remote_post with HMAC headers.
PHP (functions.php)
add_action(‘save_post’, function($post_id, $post, $update){
if (wp_is_post_revision($post_id)) return;
$secret = defined(‘AI_BRIDGE_SECRET’) ? AI_BRIDGE_SECRET : ”;
if (!$secret) return;
$src = ‘wordpress’;
$ts = strval(time());
$payload = array(
‘type’ => ‘post.updated’,
‘id’ => strval($post_id),
‘slug’ => get_post_field(‘post_name’, $post_id),
‘status’ => get_post_status($post_id),
‘title’ => get_the_title($post_id),
‘updated_at’ => get_post_modified_time(‘c’, true, $post_id),
);
$body = wp_json_encode($payload);
$msg = $ts . ‘.’ . $body;
$sig = hash_hmac(‘sha256’, $msg, $secret);
$headers = array(
‘Content-Type’ => ‘application/json’,
‘X-Source’ => $src,
‘X-Timestamp’ => $ts,
‘X-Idempotency-Key’ => wp_generate_uuid4(),
‘X-Signature’ => $sig
);
$resp = wp_remote_post(‘https://api.yourdomain.com/webhooks/ingest’, array(
‘headers’ => $headers,
‘body’ => $body,
‘timeout’ => 5
));
}, 10, 3);
Downstream AI workflow example
– For post.updated, fetch content, build embeddings, update vector store, and ping cache.
– Keep external calls in workers, not in the ingest thread.
Python (handlers.py)
def handle_wordpress_post(data):
post_id = data[“id”]
# fetch full content via WP REST API if needed
# generate embeddings, upsert to pgvector / Pinecone
# warm caches or notify search index
Operational hardening
– Rate limiting: Nginx limit_req or Django Ratelimit (e.g., 10 r/s per IP or per source).
– Request size: cap at 512 KB for webhook body.
– Timeouts: 2–5s at edge, 30s upstream; ingestion must be fast (no heavy work).
– Logging: JSON logs with event_id, source, idem_key, trace_id.
– Tracing: OpenTelemetry (propagate traceparent via headers into task metadata).
– Metrics: count accepts, rejects, duplicates, task successes/failures, DLQ depth.
– Secrets: store in AWS Secrets Manager or SSM Parameter Store; rotate quarterly.
– Network: if possible, PrivateLink/VPC endpoints for high-volume producers.
– Backfill: support manual requeue by event_id with an admin command.
– Rollouts: canary new consumers; keep handlers stateless and versioned.
Testing checklist
– Unit: signature verification, serializer validation, idempotency collisions.
– Integration: end-to-end from WordPress to Celery worker with localstack SQS.
– Chaos: duplicate deliveries, out-of-order events, large payloads, 429 from downstream APIs.
– Security: replay beyond time window, wrong signature, missing headers.
– Load: 500 rps burst; confirm ingestion stays max task time.
– Use DLQ for poison messages; set alarms on DLQ depth > 0.
What this enables
– Reliable WordPress-to-AI pipelines (content enrichment, search, translations).
– Clean integration with CRMs and payment systems for event-driven automations.
– A consistent ingestion contract your team can extend safely.