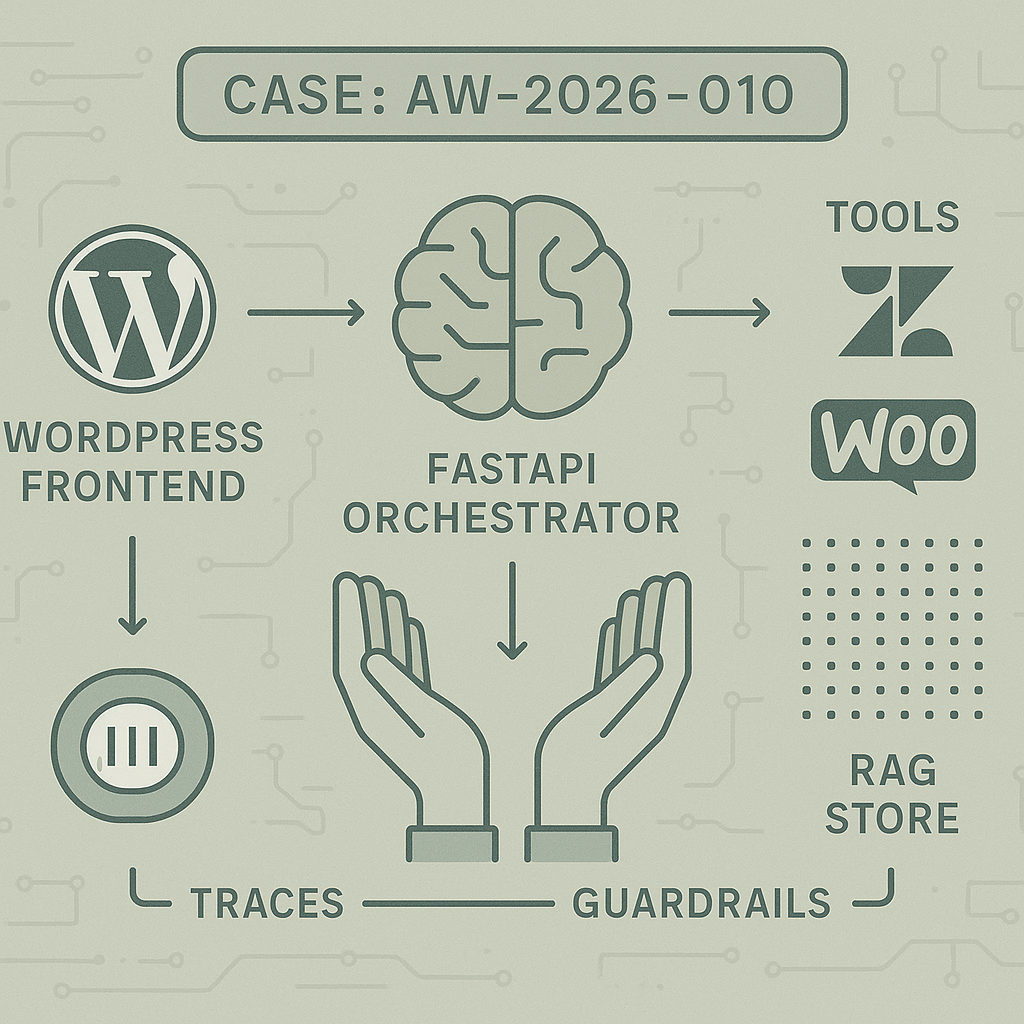
This post shows a concrete way to ship a customer support chatbot on WordPress using a Brain+Hands architecture. It focuses on reliable tool use, fast responses, and safe fallbacks—so it works in production, not just demos.
High-level goals
– Sub-2s median response on cached answers; proxies to FastAPI with service token.
– Admin settings: API base URL, agent_id, public rate caps, UI messages.
System prompt (trimmed)
– “You are the Support Agent for . Objectives: resolve safely, be concise, cite sources if RAG used, never invent order data.
– Tools are authoritative. If a tool returns empty, ask a targeted follow-up.
– Prefer RAG answers for product info; use order API only when the user provides email + order number.
– If confidence {items: [{title, url, snippet, score}]}
– get_order_status(order_id: string, email: string) -> {status, items: […], eta, support_url}
– create_ticket(subject: string, body: string, user_email: string) -> {ticket_id, url}
– wp_get_article(slug: string) -> {title, url, excerpt}
– wp_create_draft(title: string, content: string, tags: [string]) -> {post_id, url}
All tools:
– 3 attempts with exponential backoff (100ms, 300ms, 900ms) on 5xx/timeouts
– Per-tool timeouts (1.5–3.0s)
– Circuit breaker after 5 failures/60s; Brain receives tool_unavailable=true
– Input validation + PII redaction in logs
– Idempotency keys for writes (hash of normalized input)
RAG design
– Index: product docs, policies, shipping/returns, how-tos
– Chunking: 600–800 tokens with overlap 80; hybrid search (BM25 + vector)
– Metadata: section, updated_at, policy_version, locale
– Freshness: prefer updated_at within 90 days; demote stale content
– Response shaping: cite top 1–2 sources with URLs; never paste long chunks
Conversation memory
– Short-term: last 8–12 turns in Redis keyed by session_id
– Long-term: None by default; only store minimal derived facts with TTL (e.g., locale=en-US, product=Model-X)
– PII policy: Do not persist emails/order IDs beyond session TTL unless ticket is created
Orchestration logic (pseudo)
– If user intent ∈ {order_status, refund, return} and has required fields -> call appropriate tool
– Else if intent ∈ {product_info, how_to} -> RAG then answer
– Else -> clarify with a single follow-up question
– If total budget > $0.04/turn or total time > 7s -> return concise fallback + offer ticket
– If tool_unavailable -> skip tool path, provide safe guidance, suggest ticket
Guardrails
– Schema-enforced tool inputs (pydantic)
– Output moderation on Brain final answer for PII leakage
– Allowlist of domains for citations
– Cost guard: token + tool meter per session; degrade to smaller model if exceeded
– Red-team prompts stored as regression tests
Prompt templates (snippets)
– Tool-use meta instruction: “Before calling a tool, state your intent in one sentence. After tool result, summarize and answer. Do not call the same tool twice with identical params.”
– Clarifier: “Ask exactly one targeted question if required fields are missing.”
– Citation rule: “If using RAG, include ‘Sources: ’ on one line.”
Error handling patterns
– Tool 4xx: user-correctable -> ask for missing fields
– Tool 5xx/timeout: retry; if still failing -> graceful degradation path + ticket option
– JSON parse errors: re-ask model with constrained tool schema and lower temperature
– Hallucination guard: if tool not called where required -> reject answer and replan
Performance tuning
– Use smaller model for planning (e.g., 4o-mini) and larger model for final answer only when needed
– Semantic cache: cache final answers for RAG-only turns with TTL 24h and versioned by doc hashes
– Parallelize independent tools (e.g., FAQ + inventory check) with a 2.5s overall soft budget
– Stream tokens to frontend; show “retrieving order…” status on tool calls
Deployment
– FastAPI behind API Gateway + Lambda or ECS Fargate
– Postgres + pgvector on RDS; Redis on ElastiCache
– CI/CD: run unit tests for tools, contract tests, and evaluation suites before deploy
– Observability: traces per turn, tool-level spans, model cost metrics, drop rates, p95 latency
Evaluation suite
– 50–100 scripted conversations covering: missing-order-id, stale-RAG, tool-500, policy-edge, refund vs exchange
– Metrics: exactness (domain rubric), tool accuracy, escalation rate, latency, cost/turn
– Canary: 5% live traffic for 48h with auto-rollback thresholds
Minimal FastAPI skeleton (abridged)
– POST /chat
– Validate session_id, rate limit
– Load context + RAG if needed
– Call Brain (choose model based on budget)
– Execute tools via router with retries
– Stream final tokens
– Log trace + metrics
Security notes
– Service-to-service auth (JWT) between WP and FastAPI
– Do not expose vendor API keys to the browser
– Encrypt all logs at rest; redact PII
– WordPress nonce for front-end requests
When to escalate
– Low confidence + sensitive requests (refund exceptions, legal)
– Repeated tool failures
– High-friction tasks better handled by humans
– Provide ticket link and SLA
Outcome
This blueprint is the shortest path we’ve found to a reliable, fast, and safe support agent on WordPress. Start with RAG-only answers, then add high-value tools with strict contracts and clear fallbacks. Measure everything.