Why this pattern
– WordPress is great at routing and rendering, not long-running I/O.
– AI calls are slow, variable, and expensive; they need retries, quotas, and tracing.
– The solution: push jobs to an external worker and accept results via signed webhooks.
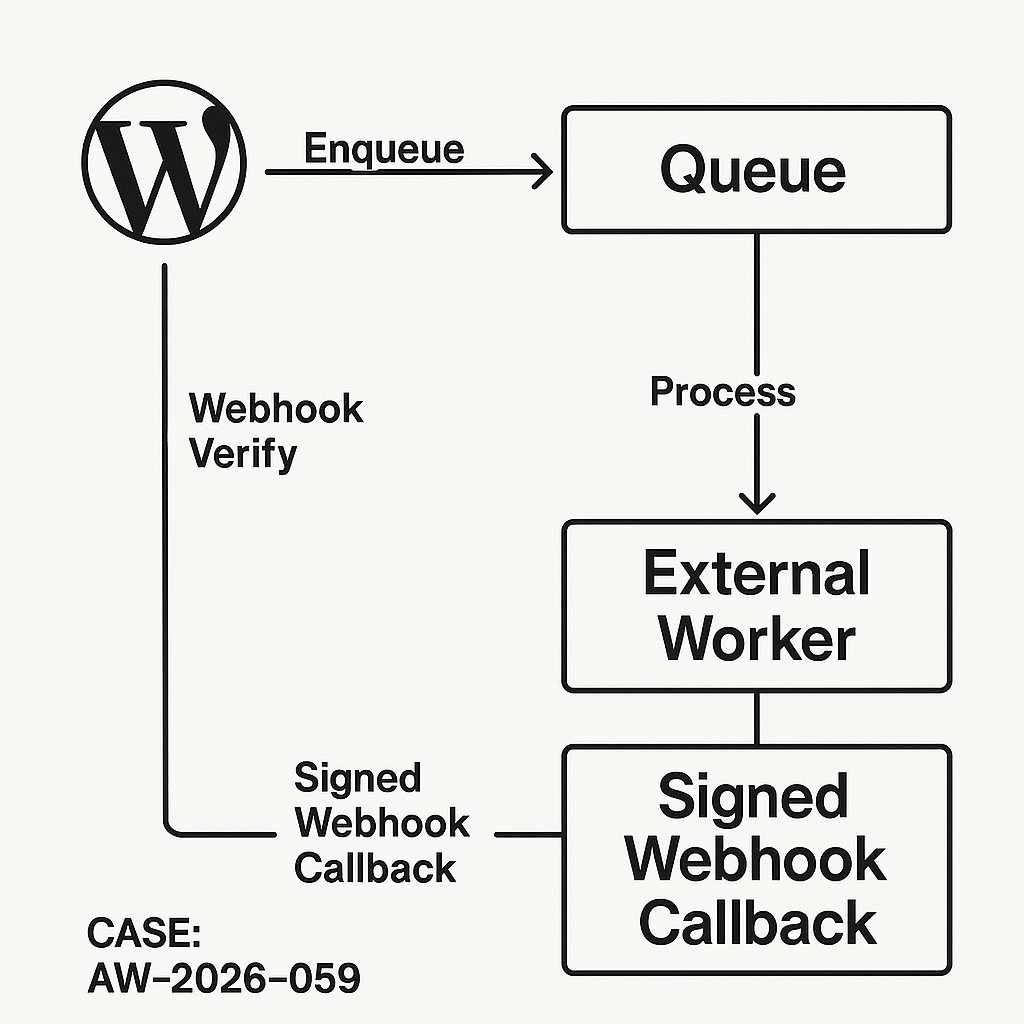
Architecture (high level)
– Client (WP admin or theme) submits an AI request to a WP REST route.
– WordPress writes a job row (pending), enqueues to an external queue (or HTTP to a worker gateway).
– Worker (Python/Node) pulls the job, calls the AI provider, then POSTs a signed webhook back to WordPress.
– WordPress verifies the signature, stores result, and invalidates relevant cache.
– Frontend polls or uses SSE/WS via a lightweight proxy for updates.
Database schema (custom table)
– wp_ai_jobs
– id (bigint PK)
– user_id (bigint)
– status (enum: pending, running, succeeded, failed)
– input_hash (char(64)) for idempotency
– request_json (longtext)
– result_json (longtext, nullable)
– error_text (text, nullable)
– created_at, updated_at (datetime)
– idempotency_key (varchar(64), unique)
– webhook_ts (datetime, nullable)
Create the table on plugin activation
– dbDelta with utf8mb4, proper indexes:
– INDEX status_created (status, created_at)
– UNIQUE idempotency_key (idempotency_key)
– INDEX input_hash (input_hash)
Plugin structure (minimal)
– ai-integration/
– ai-integration.php (bootstrap, routes, activation)
– includes/
– class-ai-controller.php (REST endpoints)
– class-ai-webhook.php (webhook verifier)
– class-ai-repo.php (DB access)
– class-ai-queue.php (enqueue out to worker)
– helpers.php (crypto, validation)
– Do not store secrets in options; put them in wp-config.php.
Secrets and config (wp-config.php)
– define(‘AI_WORKER_URL’, ‘https://worker.example.com/jobs’);
– define(‘AI_WEBHOOK_SECRET’, ‘base64-32-bytes’);
– define(‘AI_JWT_PRIVATE_KEY’, ‘—–BEGIN PRIVATE KEY—–…’);
– define(‘AI_QUEUE_TIMEOUT’, 2); // seconds for outbound enqueue
REST endpoint: create job (POST /wp-json/ai/v1/jobs)
– Validate capability (logged-in or signed public token).
– Build idempotency_key from client or hash(input_json + user_id + model).
– Insert row (pending).
– Enqueue to worker:
– POST to AI_WORKER_URL with signed JWT (kid, iat, exp, sub=user_id, jti=idempotency_key).
– Timeout <= 2s. If enqueue fails, leave job pending; a retry worker (Action Scheduler) can re-enqueue.
– Return { job_id, status: "pending" }.
Example: tiny enqueue
– Headers: Authorization: Bearer
– Body: { job_id, idempotency_key, request: {…}, callback_url: “https://site.com/wp-json/ai/v1/webhook” }
Webhook endpoint: receive result (POST /wp-json/ai/v1/webhook)
– Require HMAC-SHA256 signature header: X-AI-Signature: base64(hmac(secret, body))
– Require idempotency_key and job_id in body.
– Verify:
– Constant-time compare HMAC.
– Check timestamp drift <= 2 minutes (X-AI-Timestamp).
– Enforce replay guard: cache "webhook:{jti}" in Redis for 10m.
– Update row (status to succeeded/failed, set result_json or error_text, webhook_ts).
– Return 204.
Minimal verification (PHP)
– $sig = base64_decode($_SERVER['HTTP_X_AI_SIGNATURE'] ?? '');
– $calc = hash_hmac('sha256', $rawBody, AI_WEBHOOK_SECRET, true);
– hash_equals($sig, $calc) or wp_die('invalid sig', 403);
Frontend polling pattern
– Client gets job_id, then polls GET /wp-json/ai/v1/jobs/{id} every 1–2s (cap at 30s).
– Cache-control: private, max-age=0. Use ETag from updated_at to 304 unchanged.
– Optional: stream via SSE proxied through PHP only if your infra supports long-lived requests without PHP-FPM worker starvation.
Idempotency and dedupe
– On create:
– If idempotency_key exists, return existing job.
– Also check input_hash + user_id within time window to reduce duplicates from flaky clients.
Rate limiting
– Per-user sliding window: e.g., 60 jobs/10m.
– Use wp_cache (Redis/Memcached). Key: rl:{user}:{minute-epoch}. Increment and check.
– On limit exceed, 429 with Retry-After.
Background retries
– Action Scheduler job scans pending/running older than N minutes:
– Re-enqueue if no worker ack.
– Mark failed if exceeded retry budget; store error_text.
Security checklist
– Do not accept webhooks without HMAC and timestamp.
– JWT to worker uses short exp (<=60s). Sign with ES256 or RS256; rotate keys quarterly.
– Sanitize and escape all fields when rendering.
– Disable file edits in prod; restrict wp-admin to known IPs if possible.
– Log minimal PII; encrypt sensitive request_json fields at rest if needed (sodium_crypto_secretbox).
Performance considerations
– Never call AI providers inside a WP page render path.
– Outbound enqueue must be non-blocking (<2s). Use Requests::post with short timeouts and no redirects.
– Store only necessary parts of result_json; large blobs to object storage (S3) with signed URLs.
– Use indexes to keep dashboard queries fast; paginate admin list by created_at DESC.
– Cache job summaries with wp_cache_set on read path; invalidate on webhook.
Worker reference (Python, outline)
– Pull from queue, call provider with circuit breaker and retry/backoff (e.g., 100ms→2s jitter).
– On completion, POST result to callback_url with:
– Headers: X-AI-Signature, X-AI-Timestamp
– Body: { job_id, idempotency_key, status, result_json, usage: {tokens, ms} }
– Keep results small; upload big artifacts elsewhere first.
Minimal job table index DDL
– INDEX status_created (status, created_at)
– INDEX user_created (user_id, created_at)
– UNIQUE idempotency_key (idempotency_key)
Observability
– Add a request_id to all flows; return it to client.
– Store provider latency, tokens, and error codes in result_json. Useful for cost/perf dashboards.
– Emit Server-Timing headers on job reads: worker;dur=123,provider;dur=456.
Admin UI ideas
– List jobs with filters (status, user, model).
– Re-enqueue button (capability checked).
– Export CSV of usage by date/user.
Deployment checklist
– HTTPS everywhere; verify real client IP behind any CDN.
– Set AI_WEBHOOK_SECRET via environment, not version control.
– Protect webhook with allowlist of worker IPs if static.
– Enable object cache. Prefer Redis with persistence.
– Load test: 200 req/s create → ensure PHP-FPM pool and DB connections stay healthy.
– Back up the table and rotate old rows to cold storage monthly.
What to avoid
– Synchronous AI calls in templates.
– Storing provider keys in options.
– Webhooks without signature or timestamp.
– Unbounded job payload sizes.
This pattern scales from small sites to high-traffic publishers, keeps your PHP requests fast, and centralizes reliability and security where they belong: in the worker and webhook boundary.
This is a fantastic and much-needed pattern for handling these kinds of heavy tasks in WordPress. For the external queue component, do you generally prefer a managed service like SQS or a self-hosted option like Redis?
If you can use a managed service, SQS is usually the safer default: it’s durable, scales without tuning, and failure modes are well-understood (at the cost of slightly higher latency, AWS dependency, and some operational complexity around IAM/VPC). Redis (self-hosted) is great when you need very low latency, simple local dev, or already run Redis for caching—but you’re taking on durability/HA, backups, and “what happens during failover” engineering if you want it to behave like a true queue.
Recommendation: **SQS for production workloads where jobs must not be lost and you want minimal ops burden**; **Redis when you control the whole stack, need sub-second responsiveness, and can accept more operational responsibility (or occasional loss if not configured for persistence)**.
Rule of thumb: **small team / unpredictable load / “never drop jobs” → SQS**; **single-node or tightly controlled infra / predictable load / you already operate Redis well → Redis**.
Thank you for the clear distinction; that rule of thumb is incredibly helpful.