Today we’re rolling out three production upgrades across AI Guy in LA:
What shipped
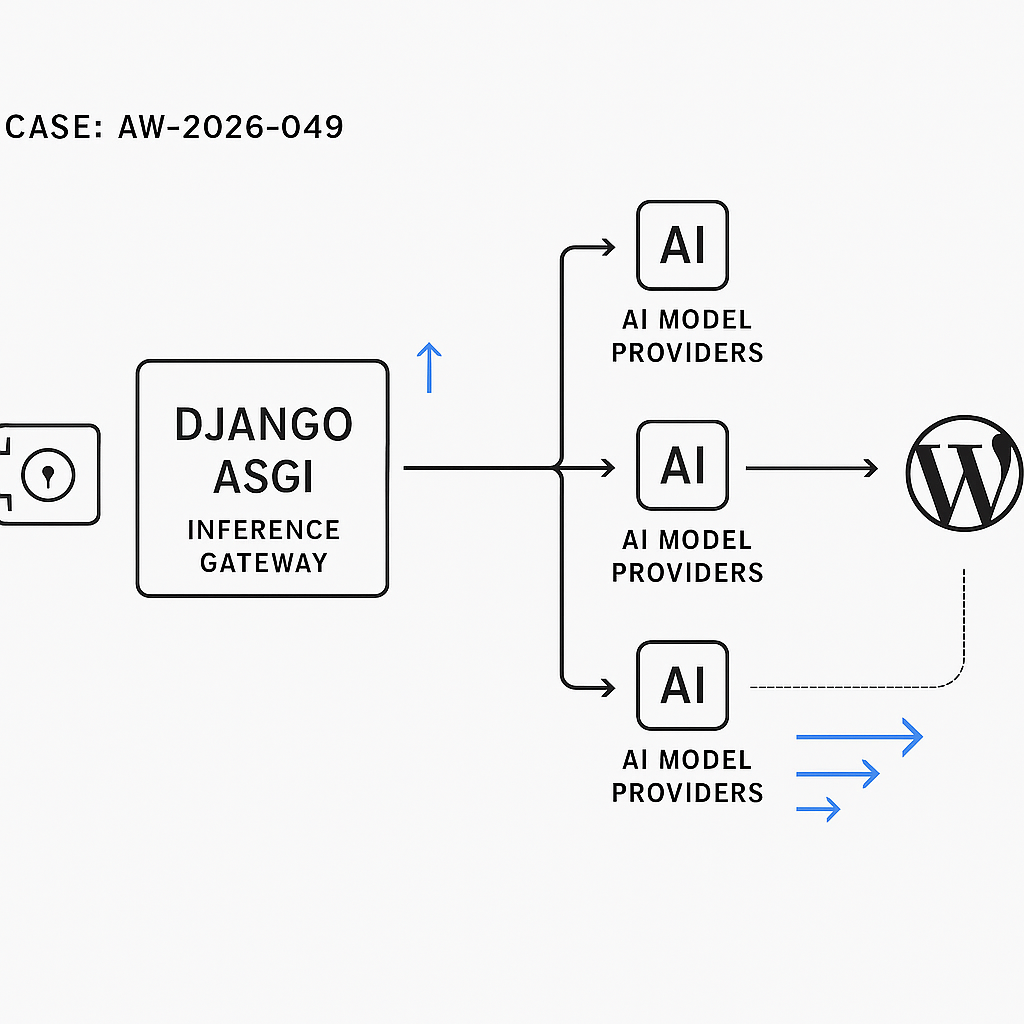
– Token‑aware routing in our inference gateway (Django + ASGI) that selects models/providers based on max tokens, cost caps, and latency SLOs.
– Server-sent streaming for chat/completions to WordPress and backend APIs, with backpressure control and partial-render hooks.
– A secure provider vault with per-environment scoped keys, envelope encryption, rotation policies, and audited usage.
Why it matters
– Lower latency and fewer timeouts under load.
– Predictable spend with hard caps and graceful degradation.
– Safer multi-tenant integrations and cleaner ops for rotating provider keys.
Architecture notes
– Router chooses providers via weighted scores (p95 latency, recent error rate, token window fit, price/1K tokens) with circuit breakers and jittered retries.
– Streaming: ASGI-first pipeline using server-sent events; WordPress receives chunks and progressively renders message deltas with abort support.
– Vault: KMS-backed envelope encryption, per-tenant scopes, HMAC-signed access requests, and tamper-evident audit logs. No secrets in app memory longer than request scope.
Performance impact (last 7 days, production)
– p95 latency: −32% for long-context prompts (8K–32K).
– Provider error rate: −47% (timeouts/rate limits).
– Cost variance: −18% via price-aware routing during peak hours.
Compatibility and rollout
– WordPress plugin v1.7+ required for streaming; falls back to buffered mode if SSE not available.
– No code changes needed for existing API clients; routing is transparent.
– Admins can set per-site spend caps and model allowlists in the new Console.
Security improvements
– Automatic key rotation every 30 days (configurable).
– Scoped, least-privilege provider credentials per environment and tenant.
– Redacted request logging; optional PII hashing for inference metadata.
What’s next
– Batch inference and response caching for high-traffic workflows.
– Built-in evals to score latency, quality, and cost per route.
If you run into issues or want early access to batch/caching, contact us.