This is a production pattern I use for customer support agents that answer FAQs, triage tickets, and trigger workflows (refunds, RMA, status checks) across web chat, email, and Slack. It separates Brain (reasoning) from Hands (tools), runs on Django + Celery + Redis, and is observable, testable, and safe.
Core goals
– Deterministic routing and tool usage
– Strong guardrails, timeouts, and fallbacks
– Telemetry and replay for every decision
– Multi-tenant, multi-channel, cost-aware
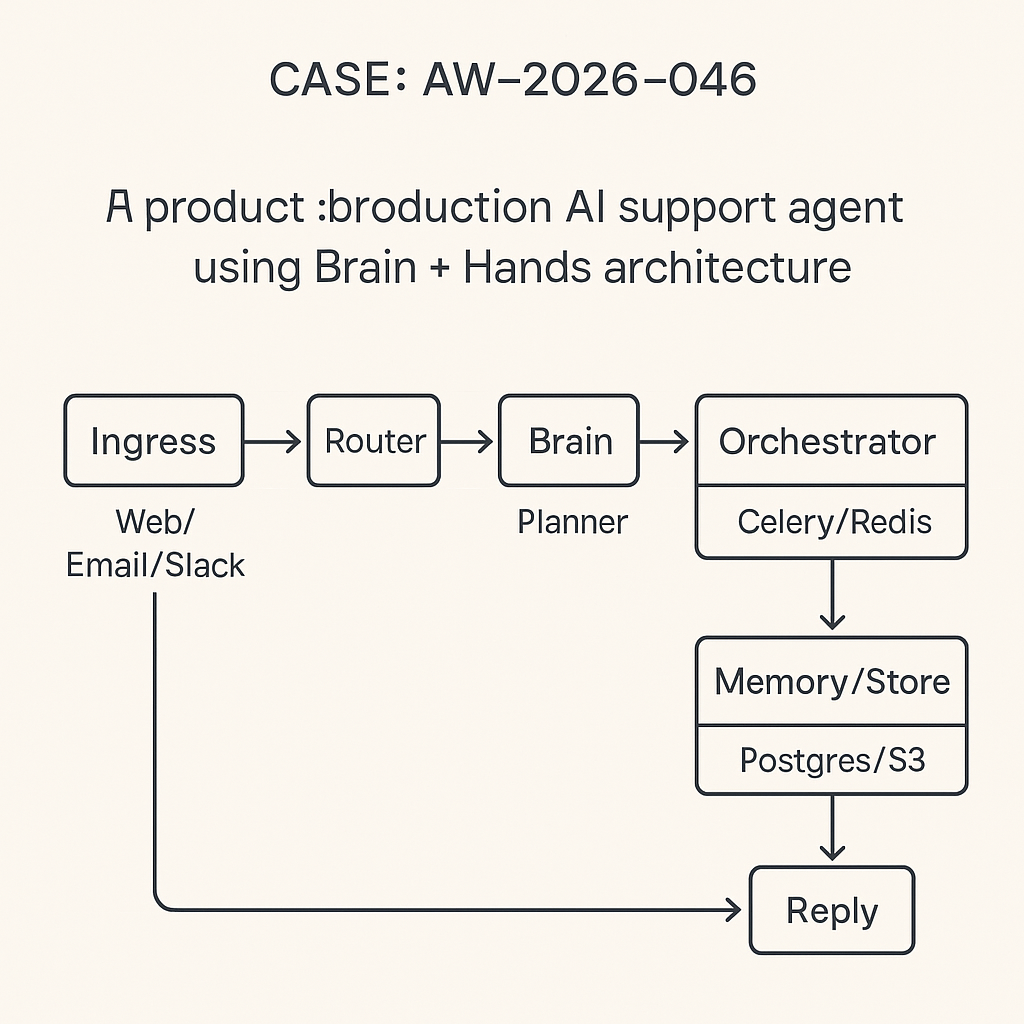
High-level architecture
– Ingress: Web chat (WebSocket/REST), Email (inbound webhook), Slack (Events API).
– Router: Normalizes messages to a canonical envelope and selects an agent profile.
– Brain: LLM planner (reasoning) that decides intent and tool calls via constrained JSON.
– Hands: Tool layer (pure functions) with validation, auth, and rate limits.
– Memory: Short-term (conversation window), long-term (vector store), and case state (Postgres).
– Orchestrator: Celery tasks for async tool calls, retries, and circuit breakers.
– Store: Postgres (state/logs), Redis (queues/locks), S3 (artifacts/transcripts).
– Observability: OpenTelemetry traces, structured logs, per-step timing and cost.
Data contracts
– MessageEnvelope: {tenant_id, channel, user_id, session_id, text, locale, attachments[], metadata{}}
– BrainPlan (strict tool schema): {intent, steps:[{tool, args, on_error}], final_answer, citations[]}
– ToolResult: {tool, ok, data|error, cost_ms}
– TraceEvent: {correlation_id, span, data, ts}
Brain + Hands separation
– Brain never mutates external systems. It plans.
– Hands are the only side-effect layer, gated by policy and schemas.
– Planner outputs are JSON that must parse and validate or are rejected.
Minimal Django models
– AgentSession(id, tenant_id, channel, user_id, status, last_seen_at)
– Message(id, session_id, role, content, tokens, cost_usd, latency_ms)
– ToolCall(id, session_id, tool, args_json, status, error, latency_ms)
– CaseState(id, session_id, intent, priority, properties_json)
– AuditLog(id, session_id, event_type, payload_json)
Routing (deterministic)
– Exact-match tenant policy first (e.g., SLA, hours, forbidden tools)
– Channel constraints second (e.g., Slack safe mode)
– Intent classifier last (small local model or regex first-pass)
Tool design
– Every tool is a small, idempotent function with:
– Pydantic schema for args and output
– Timeout, retry policy, circuit breaker
– Auth scope mapping per tenant
– Rate limit token bucket (Redis)
– Redaction rules for logs
– Example tools: get_order_status, create_ticket, process_refund, faq_search, escalate_to_human
Example: tool schema (Pydantic)
class GetOrderStatusArgs(BaseModel):
order_id: constr(strip_whitespace=True, min_length=6, max_length=32)
class GetOrderStatusOut(BaseModel):
status: Literal[“processing”,”shipped”,”delivered”,”cancelled”]
eta: Optional[str]
last_update: str
Brain contract (constrained JSON)
system_prompt (short):
– You are the Planner. Decide intent and tools using the given schemas.
– Use at most 2 tools before responding.
– If confidence plan_message -> execute_tools -> render_answer -> dispatch_reply
– Each step emits a trace span with timing, token usage, and cache hits.
Sample Django/Celery skeleton
# tasks.py
@app.task(bind=True, soft_time_limit=5)
def plan_message(self, envelope_id):
env = load_envelope(envelope_id)
context = build_context(env) # last N messages, case state, tenant policy
plan_json = call_planner(context) # with JSON mode + schema
plan = validate_plan(plan_json)
save_plan(plan)
execute_tools.delay(env.session_id, plan)
@app.task(bind=True, soft_time_limit=10, max_retries=1)
def execute_tools(self, session_id, plan):
results = []
for step in plan[“steps”]:
res = run_tool_safe(session_id, step) # timeout, retry, circuit breaker
results.append(res)
if not res[“ok”] and step.get(“on_error”) == “escalate_to_human”:
queue_handoff(session_id)
return
render_answer.delay(session_id, plan, results)
@app.task
def render_answer(session_id, plan, results):
answer = build_answer(plan, results) # template + grounded facts
persist_and_dispatch(session_id, answer)
Tool runner (guardrails)
def run_tool_safe(session_id, step):
tool = TOOL_REGISTRY[step[“tool”]]
args = tool.args_model(**step[“args”]) # validation
with circuit(tool.name).call(timeout=2):
data = tool.fn(args)
out = tool.out_model(**data)
return {“tool”: tool.name, “ok”: True, “data”: out.dict(), “cost_ms”: …}
Memory strategy
– Short-term: windowed retrieval of last K messages with role-aware pruning.
– Long-term: vector store of FAQs and policies (bm25 + embeddings). Tools: faq_search(query) returns top-3 chunks with source URLs.
– Case state: lightweight JSON with intent, artifacts, and SLA flags.
Hallucination control
– Tools return authoritative facts. Answers must cite tool outputs or approved docs.
– If no citation or tool data, say “I’m not certain” and escalate or ask for clarification.
– Instruction: never fabricate order IDs, dates, or amounts.
Cost and latency
– Use small planning model for intent; large model only when required.
– Cache embeddings and tool results (e.g., memoize get_order_status 60s).
– Token budgeting: truncate history by tokens, not message count.
– Parallel tool calls when independent (fan-out in Celery group).
Error handling and fallbacks
– Timeouts: 2s per tool; 6s end-to-end target.
– Retries: 1 retry for transient 5xx; no retry for 4xx.
– Circuit breaker: open after 3 failures/60s per tool+tenant.
– Safe response on failure with human handoff ticket ID.
– Dead-letter queue for poisoned messages, with replay UI.
Security and privacy
– Per-tenant API keys and scopes for each tool.
– PII redaction in logs; encryption at rest for transcripts.
– Prompt firewall: block secrets, card numbers, and auth tokens.
– Model routing by data classification; no PII to third-party LLMs if policy forbids.
Testing and evaluation
– Golden paths: 20-50 real transcripts turned into fixtures.
– Adversarial tests: tool failure, slow APIs, off-topic inputs.
– Offline agent eval: replay plans, measure tool accuracy, citation coverage.
– Shadow mode: run agent silently for a week before enabling auto-resolve.
Deployment notes
– Django + Gunicorn for API; Celery workers with autoscaling; Redis for queues/locks.
– Blue/green deploy; feature flags per tenant and channel.
– Observability: OpenTelemetry to your APM; log per step with correlation_id.
– Cost dashboards: tokens by tenant, intent, channel.
Example planner call (Python)
def call_planner(context):
resp = llm.chat(
model=”gpt-4o-mini”,
messages=[{“role”:”system”,”content”:SYSTEM_PROMPT},{“role”:”user”,”content”:context}],
response_format=BrainPlanSchema # JSON mode
)
return resp.parsed
What to ship this week
– Implement the data models, Tool registry, and 3 tools (faq_search, get_order_status, create_ticket).
– Wire Celery pipeline and Redis rate limits.
– Add JSON schema validation and OpenTelemetry spans.
– Run in shadow mode on Slack for one tenant.