Overview
This post shows how to ship a production-ready AI triage layer for customer support. The system auto-classifies tickets, suggests or sends replies, and routes escalations with auditable logs. It’s event-driven, API-first, and designed to be cheap, measurable, and safe.
Primary outcomes
– 40–70% reduction in first-response time
– 30–60% deflection of simple tickets
– Clear audit trail and model spend under control
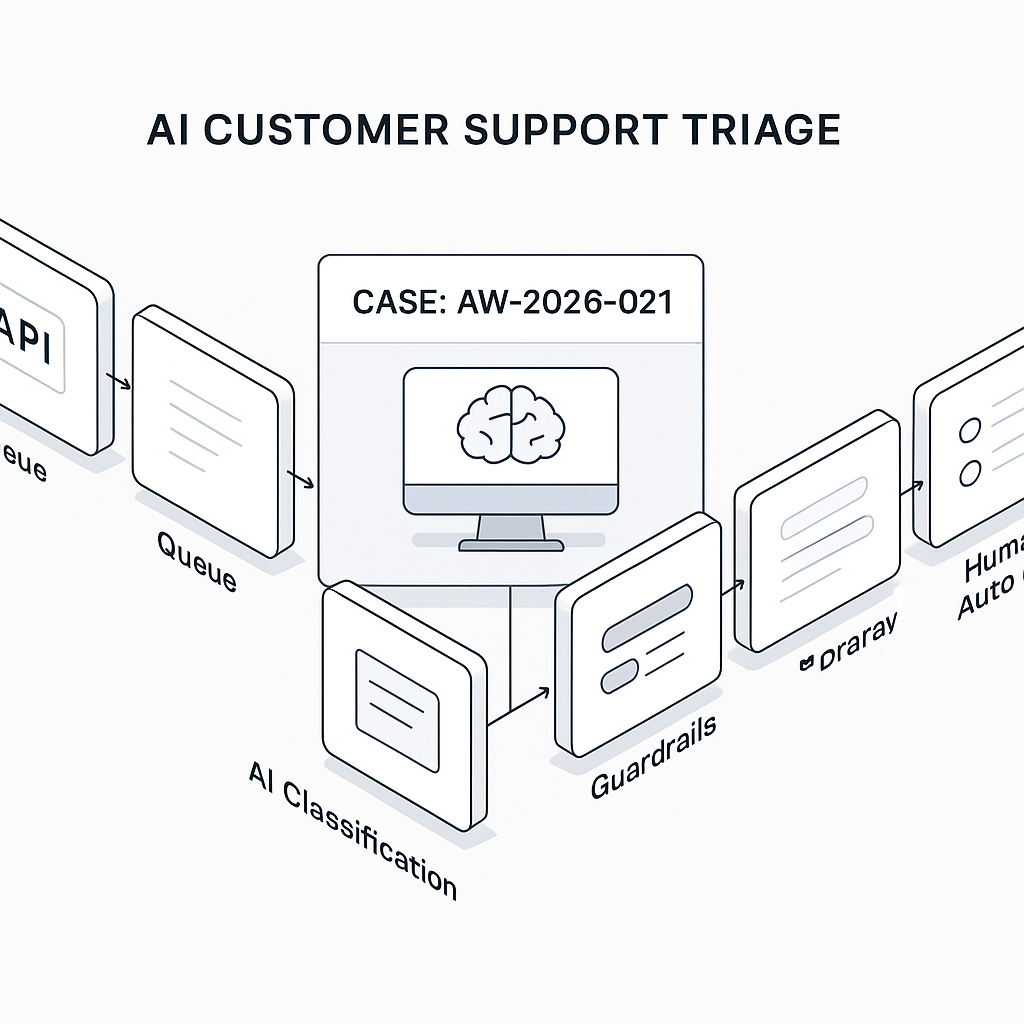
Core architecture
– Event source: Zendesk/Help Scout/Freshdesk webhook on ticket_created and ticket_updated
– Ingestion: HTTPS endpoint (FastAPI or Django) verifies webhook signatures
– Queue: Redis + Celery or AWS SQS for backpressure
– Worker: Python service handling classification, policy checks, and generation
– Models: One small classifier + one responder model with function-calling
– Retrieval: Company policy/KB in pgvector or Pinecone
– Store: Postgres for tickets, decisions, prompts, costs, metrics
– Outbound: Help desk API to post internal notes, public replies, and field updates
– Observability: OpenTelemetry traces + structured JSON logs + prompt/response warehouse
Data model (minimal tables)
– tickets(id, external_id, channel, subject, body, customer_id, created_at)
– triage_decisions(id, ticket_id, intent, priority, sentiment, confidence, action, created_at)
– generations(id, ticket_id, role, prompt_tokens, completion_tokens, cost_usd, response_text, confidence, sent_public, created_at)
– kb_documents(id, title, text, embeddings, updated_at)
Workflow steps
1) Ingest
– Verify webhook signature (HMAC) and dedupe by external_id.
– Normalize text: strip signatures, quoted replies, PII redaction for logs.
2) Classify
– Use a small model or local classifier for intent, priority, and sentiment.
– Map intent to policy (auto, suggest, escalate).
3) Retrieve
– Embed ticket body; search top-5 docs from KB/policies/refunds/SLAs.
– Build a compact context: 4–8 bullet facts, markdown-free.
4) Draft
– Responder model generates a short, action-oriented reply.
– Enforce style guide, links, and refund policy constraints via function-calling.
5) Guardrails
– If confidence < threshold or policy requires, mark as suggest_only.
– Block prohibited actions (discount/refund) without approval token.
6) Deliver
– Post internal note with: intent, confidence, sources, suggested reply, buttons (Approve & Send, Edit).
– For high-confidence macros (password reset, shipping ETA), auto-send and log.
7) Learn
– Capture agent edits and outcomes (CSAT, reopen rate).
– Fine-tune prompt and retriever filters weekly based on error clusters.
Minimal implementation details
– Classifier: Cohere Classify, OpenAI small model, or a local MiniLM + logistic regression.
– Responder: GPT-4o-mini or equivalent cost-effective model with JSON mode.
– Embeddings: text-embedding-3-small; store in Postgres + pgvector for simplicity.
– Rate limits: Token budget per ticket; concurrency via queue; exponential backoff.
– Secrets: Store provider keys in AWS Secrets Manager or Django encrypted fields.
Prompt patterns
System (responder):
– You are SupportResponder. Output concise, factual replies. No promises or discounts. Use only the provided sources. If missing info, ask one clarifying question. Return JSON: {reply, confidence, needs_approval, citations}.
User context:
– Ticket:
– Detected intent:
Function-calling actions
– get_order_status(order_id)
– create_rma(ticket_id)
– get_account_plan(email)
– request_refund(ticket_id, amount) [requires approval_token]
Guardrails and policy layer
– Hard caps: max refund amount by tier; discount disabled in AI.
– Redaction: Mask card numbers, SSNs, access tokens in logs.
– Confidence gating: send_public only if confidence >= 0.82 and no unresolved variables.
– Toxicity check: If customer is hostile, require human review.
– SLA routing: Enterprise + P1 → immediate escalation, no AI reply.
Cost control
– Use small classifier first; skip responder if intent is “routing_only.”
– Truncate context to most similar 600–800 tokens.
– Batch embeddings; cache across ticket threads.
– Track cost_usd per generation; alert if daily spend > threshold.
Operational metrics (log and dashboard weekly)
– FRT reduction (baseline vs. post)
– Auto-send rate and acceptance rate of suggestions
– Edit distance between AI draft and final sent message
– CSAT delta and reopen rate
– Cost per resolved ticket and model cost as % of support payroll
Case example (SMB e-commerce, 8 agents)
– Volume: 250 tickets/day; 45% simple (order status, address change, ETA)
– Baseline triage: 3 min/ticket → 12.5 hours/day
– After AI:
– 38% auto-sent replies at 0.85+ confidence
– 34% suggested replies approved without edits
– FRT: 1h 12m → 14m
– Edits median 7 words
– Model cost: ~$12/day (embeddings + generations)
– Time saved: ~8.9 agent-hours/day
– Labor value at $30/hr: ~$267/day
– Net after model cost: ~$255/day; ~5.6x ROI monthly
Failure modes and mitigations
– Hallucinated policy: Require citation IDs; block send if citation mismatch.
– Wrong order lookup: Validate order_id format + 404 handling before reply.
– Overlong replies: Enforce 90–140 words; no more than 3 bullets.
– Language mismatch: Detect locale; route to bilingual agent if missing.
Deployment checklist
– Webhook auth and idempotency keys
– Observability: traces, token counts, latency, and cost
– Backpressure: queue depth alarms
– A/B flag: per-intent confidence thresholds
– Playbooks: weekly KB refresh; misclassification triage
– Security: PII masking, SCIM/SSO for dashboards, least-privilege API keys
Rollout plan
– Phase 1: Suggest-only for 2 intents (order status, password reset)
– Phase 2: Auto-send for those intents at confidence >= 0.85
– Phase 3: Add billing and returns with approval tokens
– Phase 4: Expand languages, add proactive outreach on shipping delays
Code skeleton (Python, illustrative)
– Ingest endpoint:
– Verify signature
– Push job to queue with ticket payload
– Worker:
– classify(ticket)
– retrieve_context(ticket)
– draft_response(context)
– guardrails(policy, confidence)
– deliver(note or public reply)
– record metrics and costs
Takeaway
Start narrow with two high-volume intents, wire in strict guardrails, measure edits and reopen rate, and scale by policy maturity. Keep the stack simple, logs structured, and thresholds adjustable per intent. That’s how AI triage becomes a dependable, cost-effective part of support operations.
Thank you for sharing this practical and well-defined architecture; the focus on measurable outcomes is particularly helpful. What key metrics do you use to monitor the quality and accuracy of the AI’s classifications and suggested replies over time?
For classification and reply suggestions, are you mainly optimizing for *customer impact* (CSAT/containment) or *risk control* (wrong routing, policy breaches), and do you already have a “ground truth” label source (agent tags + audits)?
A concise metric set that’s worked well in practice:
– **Classification:** accuracy/F1 by class, **calibration** (ECE/Brier + confidence-vs-accuracy), **drift** (input/topic distribution + performance by time window), and **escalation correctness** (false negatives on “must-escalate”).
– **Reply suggestions:** **human override rate** (edit/reject), **CSAT** on assisted vs unassisted tickets, **containment/deflection** rate, and **policy/safety violations** caught by checks (plus any post-hoc incidents).
To track over time: log every decision with model version + confidence, then do **weekly stratified sampling** (by intent, confidence bucket, and high-risk categories) for human audits, and maintain rolling dashboards (7/30/90 days) with alert thresholds when calibration or override rates shift.
Thank you for this excellent framework; we’re prioritizing risk control initially while establishing our ground truth labels.