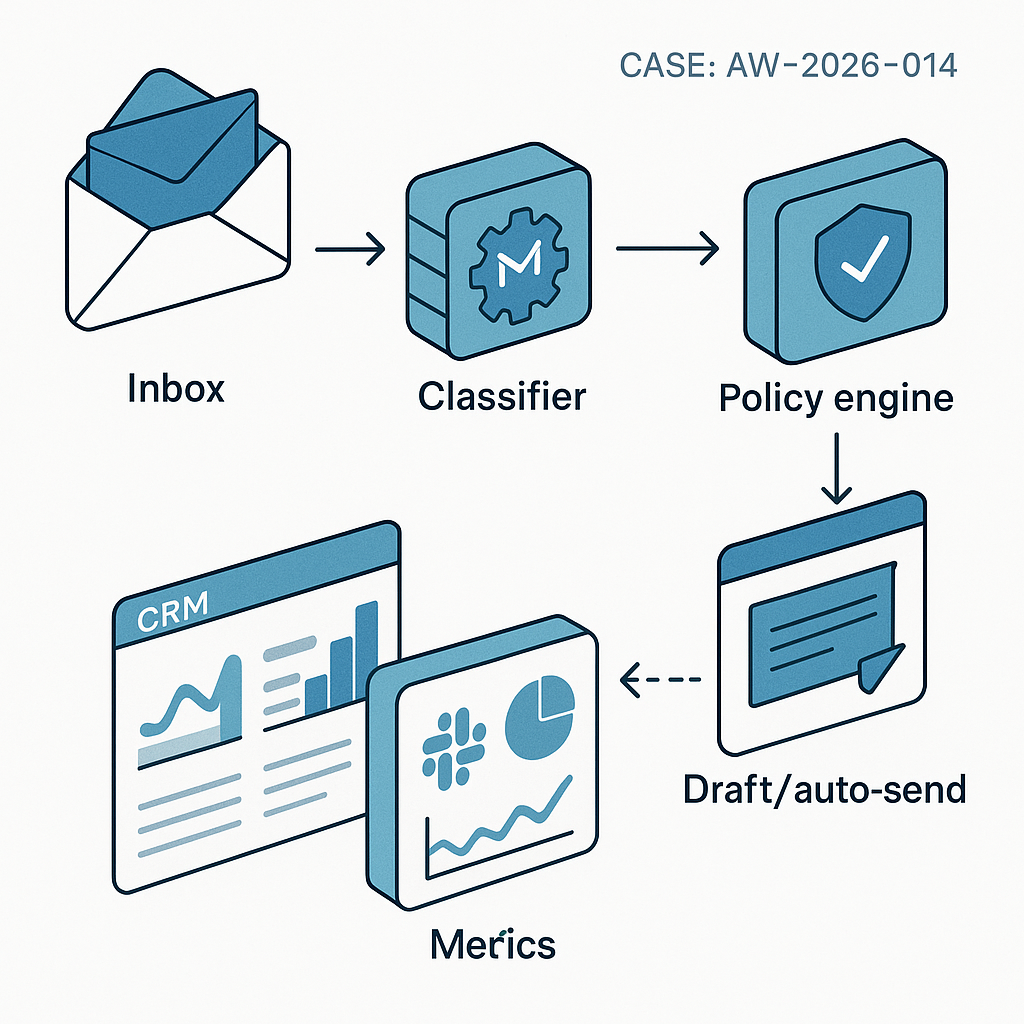
Problem
Support, sales, and ops inboxes drain time with repetitive triage and templated replies. Off-the-shelf “AI inbox” tools are opaque and hard to control. We want a system we can host, audit, and tune.
Outcome
A queue-driven service that:
– Classifies incoming emails by intent, urgency, and owner
– Auto-replies when safe, drafts replies when not
– Enriches contacts and logs everything to CRM
– Measures precision, latency, and savings
Core architecture
– Ingestion: Gmail/Google Workspace or Outlook webhook to Pub/Sub/SQS
– Processing service: Python (FastAPI) workers pull from queue
– Models: Hosted LLM (gpt-4o-mini or Claude Haiku) for NLU + drafting; small local model optional for lightweight classification
– Policy engine: JSON rules for sender allowlists, domains, SLAs, PII handling
– Templates: Jinja2 response library with slot-filling
– Human-in-the-loop: Drafts to Slack thread or Helpdesk (Zendesk/Help Scout) for one-click approve/edit/send
– Persistence: Postgres for message states; Redis for idempotency, rate limits
– Integrations: CRM (HubSpot/Pipedrive), Helpdesk, Slack, Calendar, Knowledge base
– Observability: OpenTelemetry traces; Prometheus metrics; S3/Blob for redacted samples
– Security: Service account with least privilege; KMS for secrets; structured redaction
Flow
1) New email hits webhook → normalized payload pushed to queue
2) Pre-filter: spam/auto-replies; dedupe via Redis
3) Classifier LLM (cheap, fast) → {intent, urgency, owner, policy_flags}
4) Router: apply policies and business rules
5) Response path:
– Safe and low-risk → template fill + LLM paraphrase → auto-send
– Medium risk → draft to Slack/Helpdesk with approve/edit buttons
– High risk or VIP → assign human, include suggested outline
6) Enrichment: look up contact, past tickets, open deals; light web/company data
7) Log action: CRM note, ticket updates, analytics counters
8) Post-send QA: spot-check sampling with a secondary model; tag issues
9) Feedback loop: human edits create fine-tuning examples for style and tone
Model selection
– Classifier: gpt-4o-mini or Claude Haiku for low cost/latency
– Drafting: gpt-4o-mini for most; higher-end model for complex replies
– Optional local: Llama 3.1 8B for intent tags if data residency requires
– Summaries for Slack: smallest viable model
Prompt design (concise)
System: You are an inbox triage assistant for {Company}. Output strict JSON only. Never invent facts or offers.
User: Email text + thread + CRM context + policies
Tools: Template library, company FAQ, product catalog
Guardrails:
– Allowed intents list
– No promises of discounts/SLA changes
– Redact PII before LLM calls when policy_flags include sensitive
Templates (examples)
– Scheduling: propose 2 time slots; include Calendly link if provided
– Pricing info: approved price sheet paragraphs only
– Support ack: ticket created, ETA window, links to docs
– Referral/partner: route to partnerships alias
Data model (Postgres)
– messages(id, thread_id, sender, subject, received_at, status, intent, urgency, owner, policy_flags, auto_sent boolean)
– drafts(id, message_id, draft_text, template_id, approver, decision, latency_ms)
– metrics(date, intent, auto_rate, approve_rate, revert_rate, avg_latency_ms, cost_usd)
Security and compliance
– OAuth with restricted scopes (read-only bodies + send mail); no full mailbox dumps
– Encrypt payloads in transit and at rest; KMS-managed keys
– Redact PII fields before external LLM calls when flagged
– Store minimal context; retain samples with redactions for 30–90 days only
– Audit log all auto-sends
Latency targets
– P50 triage < 1.2s, P95 < 3s
– Draft generation < 2.5s typical
– Slack approval path end-to-end < 60s
Cost model (typical SMB)
– 1,500 inbound emails/week
– 60% classified safe, 30% draft, 10% human from scratch
– With gpt-4o-mini:
– Classify pass: ~$0.0006/email
– Draft pass: ~$0.004–0.01/email
– Est. weekly spend: $12–$25
– Time saved: 6–12 hours/week per shared inbox
KPIs to track
– Auto-send precision (manual QC sample) ≥ 98% target
– Human correction rate on drafts enqueue(msg)
Worker:
msg = dequeue()
if is_spam(msg): return
features = redact(msg)
tags = llm_classify(features)
decision = route(tags, policies)
if decision.auto_send:
draft = fill_template(tags, kb, crm)
safe = lint(draft, policies)
send_email(safe)
log_metrics(…)
elif decision.needs_review:
draft = fill_template(…)
post_to_slack(draft, approve_url)
else:
assign_human(msg)
What makes this production-ready
– Queue-first for resilience and backpressure
– Clear policies over prompts; measurable thresholds
– Human control on medium/high-risk paths
– Observability by default
– Data minimization and redaction path
– Auditable outcomes tied to CRM and tickets
Where this works best
– High-volume inquiry inboxes (support@, info@, sales@)
– Teams with defined templates and policies
– Organizations needing auditability and cost control
Next steps
– Start in dry-run for one week to collect labels and tune
– Promote 1–2 intents to auto-send with strict thresholds
– Review weekly metrics; expand coverage as precision holds
This is a fantastic and practical blueprint for moving beyond opaque AI tools. For the policy engine, what was the most challenging aspect of defining the rules for when it is “safe” to auto-reply?